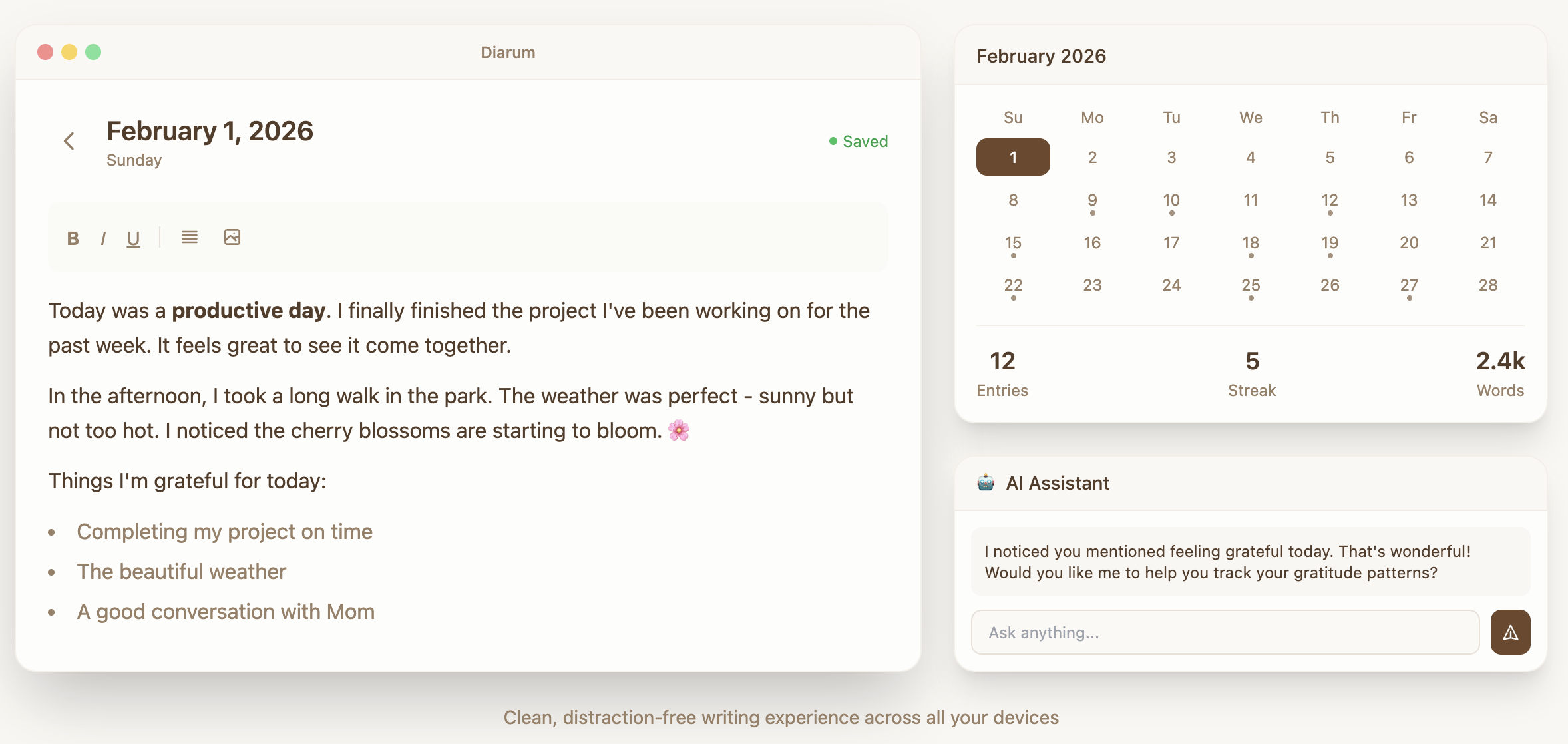
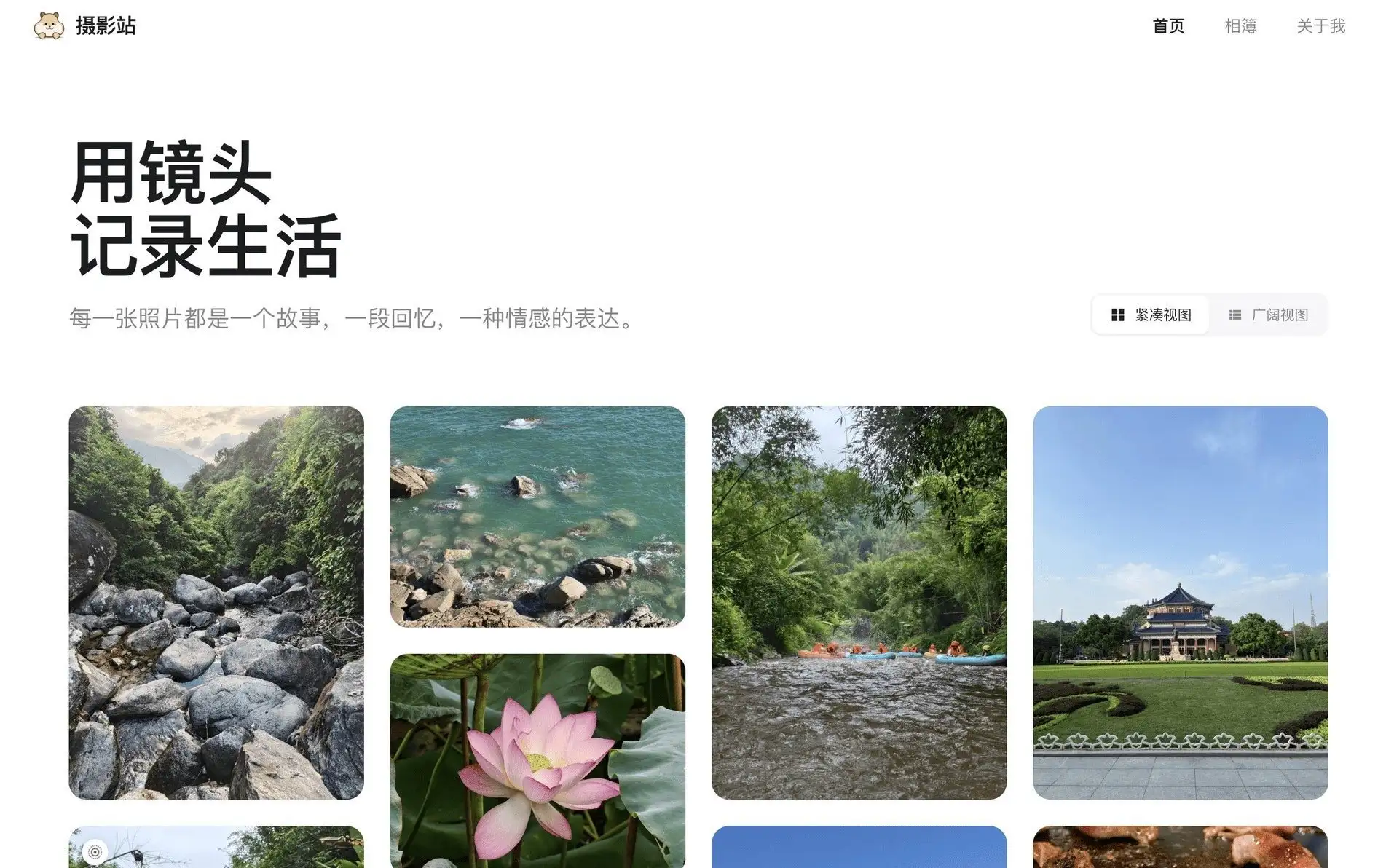
Plog – 个人摄影作品展示网站摄影站 – 个人摄影作品展示网站 用镜头记录生活的美好瞬间,分享我的摄影作品。每一张照片都是一个故事,一段回忆,一种对生活的感悟。
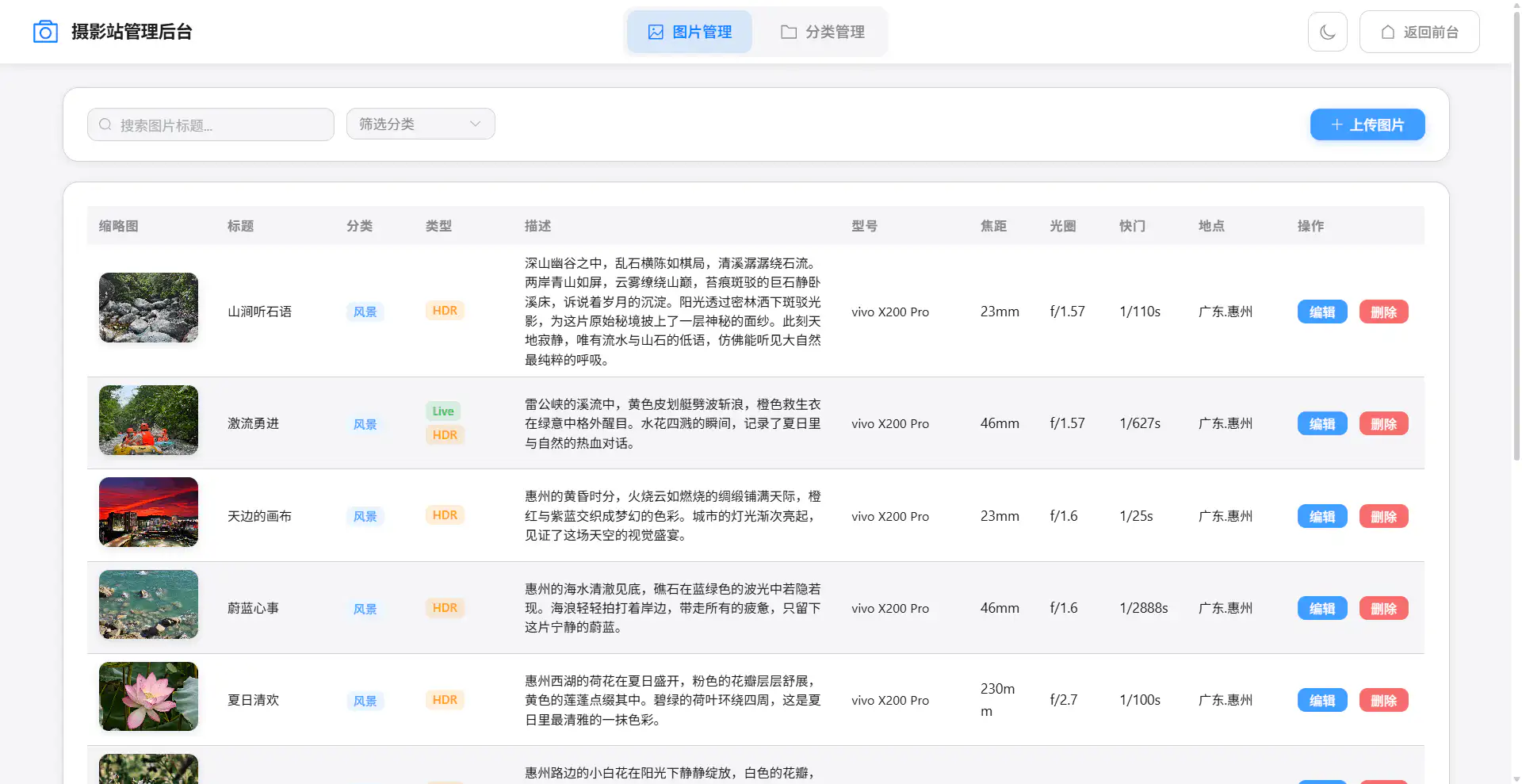
项目截图
核心特性
📱 Live Photo 支持
支持 Android Motion Photo(已测试 vivo X200 Pro):
- 自动识别和分离 – 支持多种检测方式
- XMP 元数据检测(
vivo:LivePhoto="1",GCamera:MicroVideo="1") - 二进制特征检测(兜底方案)
- 自动提取视频并保存到
uploads/live/
- XMP 元数据检测(
- HEIC 格式转换 – 自动转换为 JPG
- 交互体验
- PC 端:鼠标悬停 LIVE 标记循环播放
- 移动端:点击播放一次自动停止
- 视频控制 – 静音按钮、播放状态图标
- 管理后台 – 按住预览、类型标识、视频下载
- 兼容性说明
- ✅ 已测试:vivo X200 Pro
- ⚠️ 其他安卓手机(小米、OPPO、三星等)需自行测试
- ❌ iPhone Live Photo 暂不支持
🌈 HDR 照片支持
使用 Gain Map 技术正确渲染 HDR 照片:
- 自动检测 – 识别 Gain Map 元数据(
Item:Semantic="GainMap") - WebGL 渲染 – 高亮度图像渲染(基于 gainmap-js)
- 元数据保留 – 上传时保留完整 HDR 信息
- 标识显示 – 金色 HDR 徽章
- 兼容性说明
- ✅ 已测试:vivo X200 Pro
- ⚠️ 其他安卓手机需自行测试
- ❌ iPhone HDR 暂不支持
🎨 文件夹式 3D 相册
Apple 风格的相册展示:
- 3D 层叠效果 – 3 层照片露出,营造文件夹感
- 悬停动画 – 后层展开 + 旋转,模拟”打开”效果
- 两种显示模式 – 通过
galleryConfig.albumLayerMode配置'color'– 虚拟彩色(彩虹渐变色卡)'photo'– 真实照片(显示相册内第 2、3 张照片)
- 直接浏览 – 点击相册直接打开照片弹窗
🖼️ 液态玻璃照片弹窗
Apple 风格的照片查看器:
- 单张/多张模式 – 自动适配
- 液态玻璃导航栏 – 底部缩略图导航
- 增强模糊效果(60px blur + 200% 饱和度)
- 渐变背景 + 多层阴影
- 玻璃高光效果
- 多种滚动方式
- 鼠标滚轮:垂直转横向(0.8 倍速)
- 触摸板:双指左右滑动
- 鼠标拖动:grab/grabbing 光标
- 触摸屏:手指左右滑动
- 流畅切换动画 – 方向性滑动 + 淡入淡出
- 键盘导航 – 左右箭头切换 / ESC 关闭
- 移动端优化 – 手势滑动 + 详情面板覆盖
🎭 Apple 风格交互系统
统一的交互设计语言(src/styles/interactions.css):
- 按钮交互
- hover:上移 + 阴影增强
- active:缩放 0.95 + 快速反馈
- 图标按钮:放大 1.1 + 背景扩散
- 卡片交互
- hover:上移 4px + 放大 1.005
- active:缩放 0.98
- 过渡时间:350ms
- 链接交互
- 下划线动画:从中间向两边展开
- 导航链接:底部细线动画
- 标签交互
- hover:放大 1.05 + 轻微阴影
- 涟漪效果:点击扩散动画
- 移动端优化
- 移除 hover 效果
- 增强 active 反馈
- 禁用点击高亮
🌓 深色模式
完整的深色模式支持:
- 自动跟随系统 – 使用
prefers-color-scheme - CSS 变量系统 – 统一管理颜色
--bg-primary/--bg-secondary--text-primary/--text-secondary/--text-tertiary--border-color/--nav-bg
- 所有组件适配 – 导航栏、卡片、弹窗、表单等
- 阴影自适应 – 深色模式下阴影更深
📊 EXIF 信息管理
完整的照片元数据处理:
- 自动提取 – 使用 exifr 库
- 相机型号(Make + Model)
- 焦距(FocalLength)
- 光圈(FNumber)
- 快门速度(ExposureTime)
- ISO(ISO)
- 拍摄时间(DateTimeOriginal)
- GPS 逆地理编码 – 高德地图 API
- 自动转换为省市地址
- 格式:
广东省.惠州市.惠城区
- 表单自动填充 – 上传时自动填入 EXIF 信息
- 详情展示 – 照片弹窗中展示完整信息
🛠️ 管理后台
Apple 液态玻璃风格的管理系统:
- 图片上传 – 按钮式上传,支持预览,Live Photo 预览(按住播放),HDR 照片标识,EXIF 信息卡片式展示
- 自动处理 – 生成 800px 缩略图,保留 HDR 元数据,提取 Live Photo 视频,HEIC 转 JPG
- 图片管理 – 列表展示(Live/HDR 标签),编辑标题、分类、描述,删除同步清理文件
- 分类管理 – 添加、编辑、删除分类,图标、描述配置
- 批量检测脚本 –
npm run detect自动检测所有照片特性
🔍 SEO 优化
- 动态 Meta 标签 – 每个页面独立的标题、描述、关键词
- Open Graph – 社交分享优化
- 结构化数据 – JSON-LD 支持
- 自动生成 – robots.txt 和 sitemap.xml
🚀 性能优化
代码分割 – 管理后台独立打包
图片懒加载 – 延迟加载 + 骨架屏
路由懒加载 – 按需加载页面
缩略图分离 – 列表用小图,详情用原图
图片尺寸预留 – 避免布局跳动
项目地址
github:https://github.com/lyhxx/photography-station
demo演示站点:https://p.javai.cn/