不知道有没有动漫制作者或者动画爱好者,在制作动漫或者绘画时对人物脚部需要展示的细节有要求或者疑问,动漫脚部AI工具可以帮助你获取灵感和生成各种风格的脚部特写。
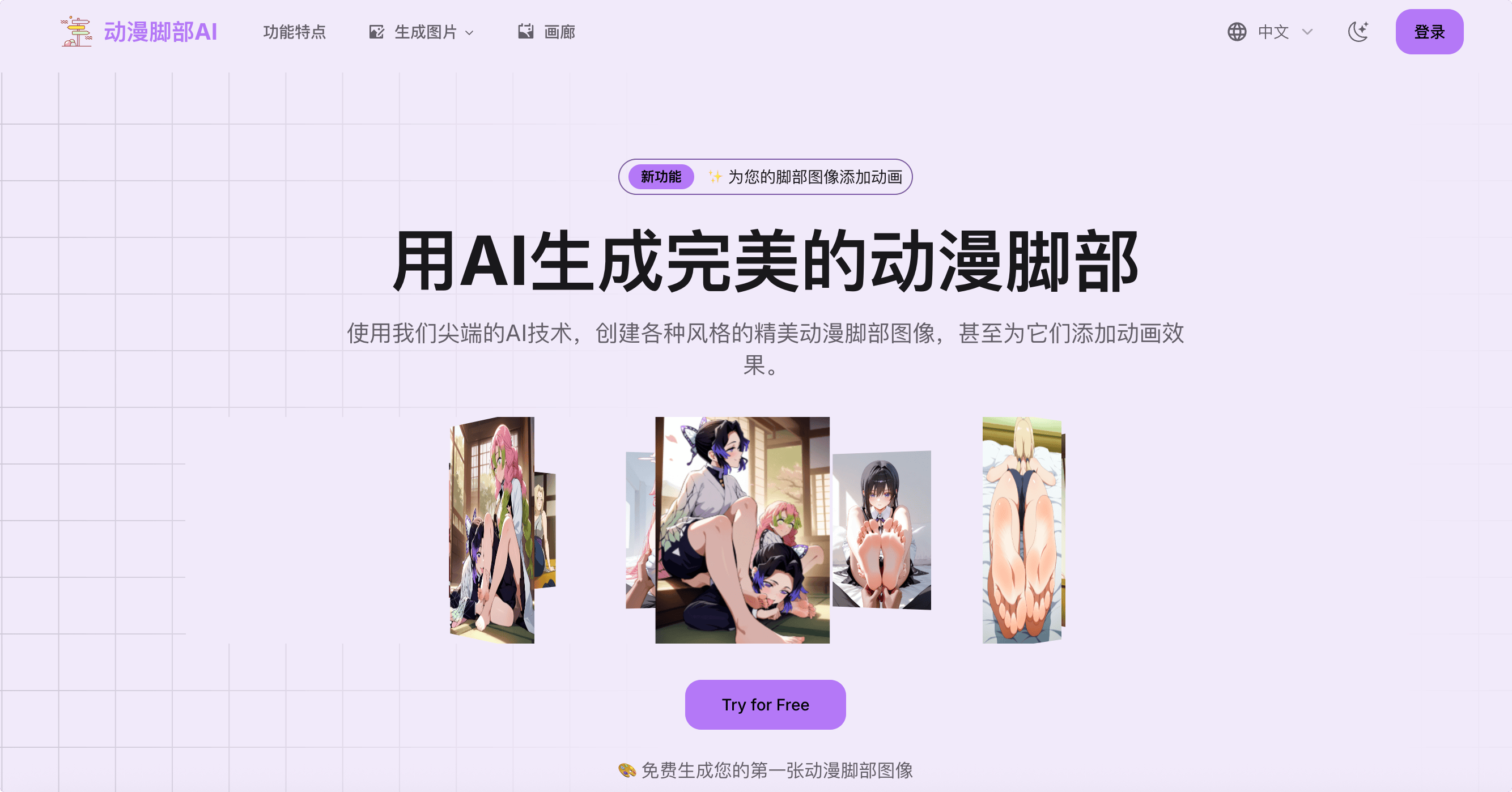
动漫脚部AI,一个可以在线生成动漫脚部图像和动画的工具,通过输入文字描述或者上传图像来生成动画。
可以用文字详细描述带有不同指甲油颜色、配饰、姿势的脚部,同时支持输入角色特征,如发色、服装或特定特征。阿喵测试了一下图像在5-10秒内就可以生成,可直接下载保存到本地,推荐!
网站截图
强大的AI推荐
不知道有没有动漫制作者或者动画爱好者,在制作动漫或者绘画时对人物脚部需要展示的细节有要求或者疑问,动漫脚部AI工具可以帮助你获取灵感和生成各种风格的脚部特写。
动漫脚部AI,一个可以在线生成动漫脚部图像和动画的工具,通过输入文字描述或者上传图像来生成动画。
可以用文字详细描述带有不同指甲油颜色、配饰、姿势的脚部,同时支持输入角色特征,如发色、服装或特定特征。阿喵测试了一下图像在5-10秒内就可以生成,可直接下载保存到本地,推荐!
每次发现新的AI工具的时候,阿喵都忍不住感慨,AI是个好东西呀,牛马打工人的福音!可以在工作和学习中给大家提供很多帮助,节省下很多脑细胞。阿喵今天想分享给大家一个AI工具箱–Nova AI工具箱。
Nova AI工具箱是一个强大的AI平台,包含了写作、学习、邮件、图表和PDF处理等多种AI工具。 它可以帮助你轻松创作内容、提高学习效率、创建思维导图、撰写专业邮件、PDF格式转换,PDF内容提取等。是一个宝藏工具箱,还有很多其他的功能供大家使用,免费,无需登录,推荐!
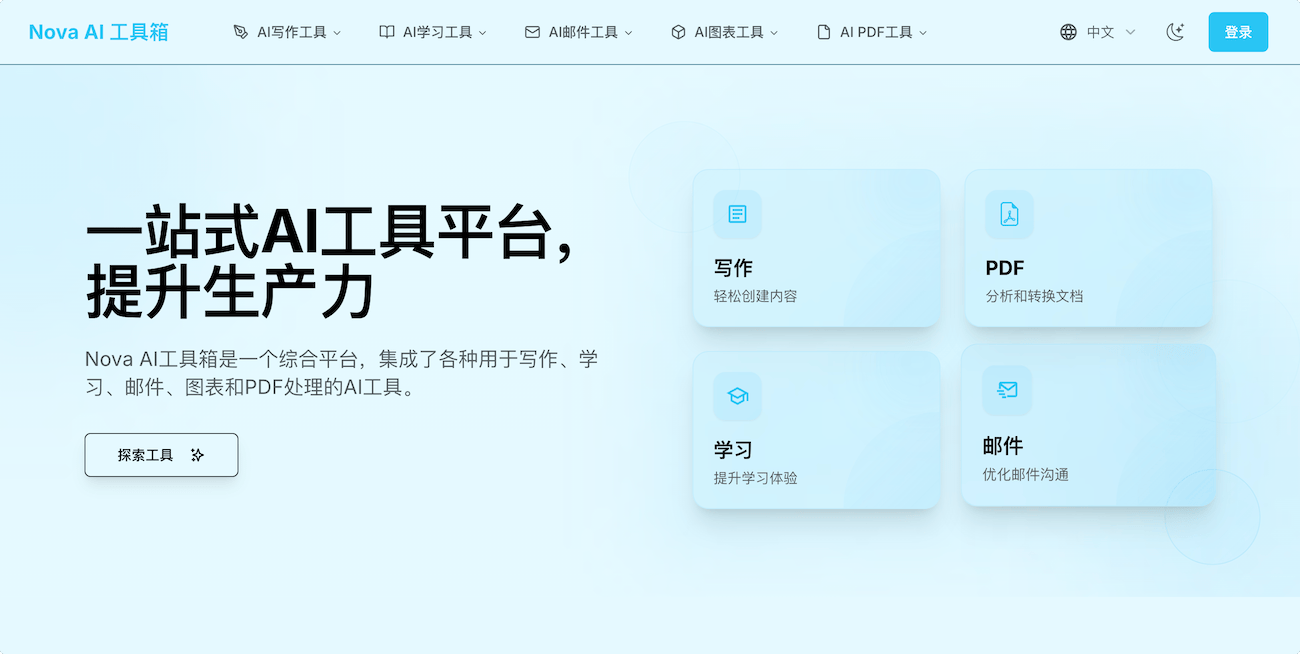
AI写作工具:支持AI段落重写工具、AI信件生成器、AI段落生成器。
AI学习工具:支持AI闪卡制作器、AI问题生成器、AI学习指南创建器。
AI邮件和图表工具:支持为任何场景撰写专业邮件,支持文本或概念自动生成思维导图,支持简单的文本指令创建专业的流程图和过程图。
AI PDF工具:支持AI PDF摘要器、支持将PDF转换为各种格式,保持格式不变。
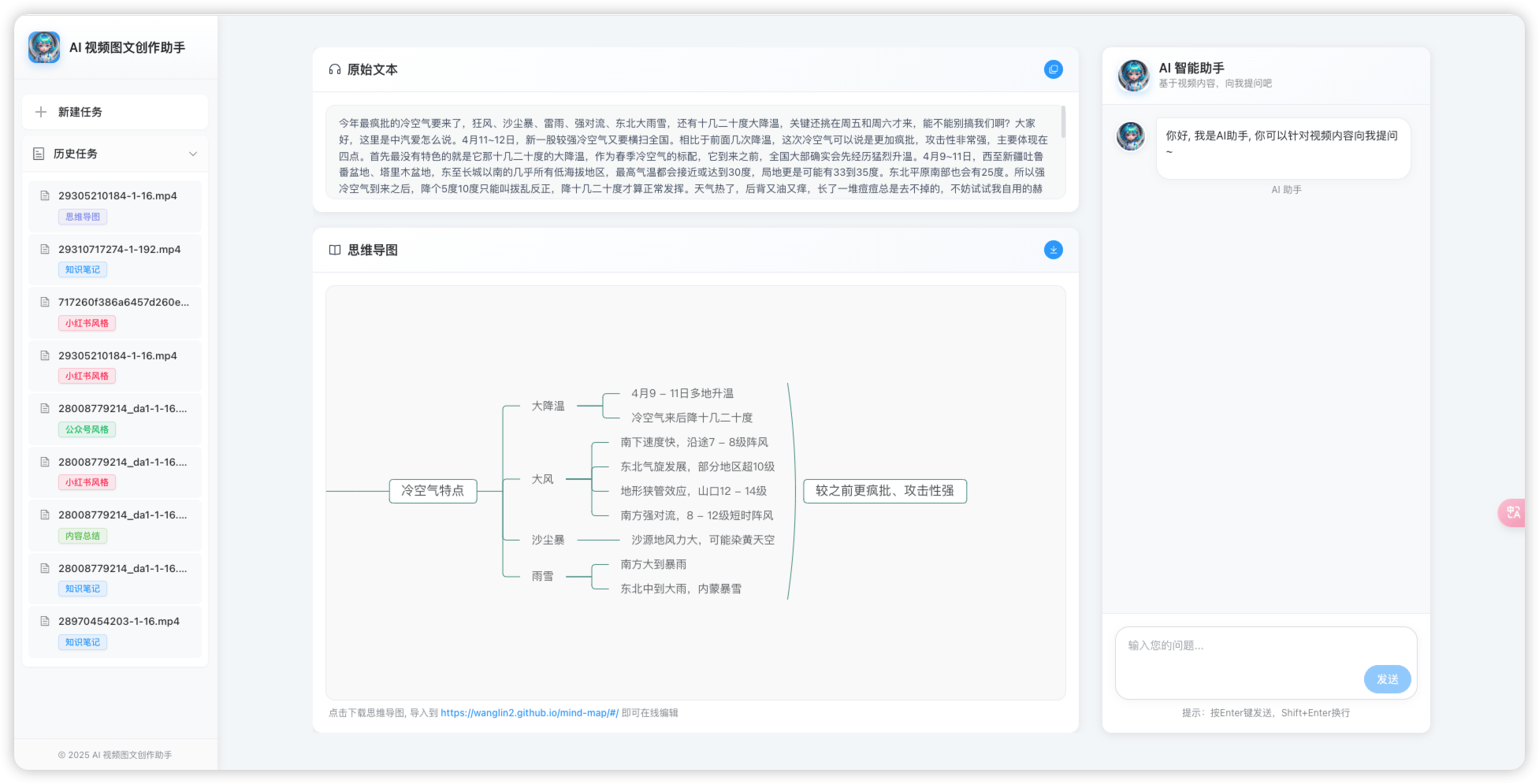
AI 视频图文创作助手基于AI大模型, 支持将基于任意视频/音频转换成各种风格的文档, 目前包括小红书、知识笔记、微信公众号和思维导图等。
如果在看完一个视频或者音频的时候,你想将视频/音频内容转换成文字,快速做内容总结,方便下次查看,AI 视频图文创作助手完全可以满足你的需求。阿喵非常心动的点是,它支持对生成的内容进行二次对话,可更详细的了解内容,并且支持将生成的思维导图导出到第三方免费的平台进行编辑和调整。
项目完全开源, 支持前后端本地部署, 无需登录注册, 任务记录保存在本地。
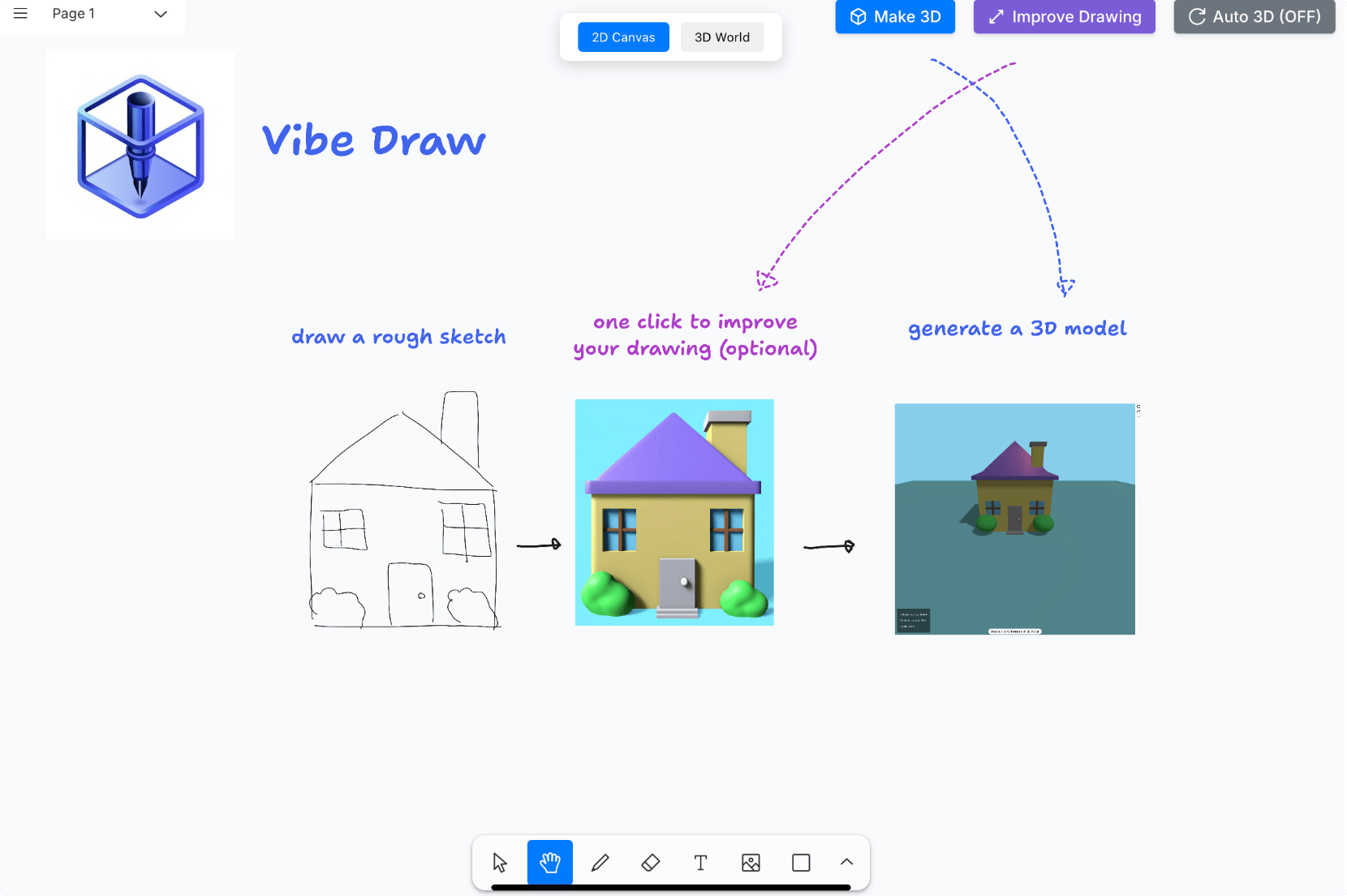
Vibe Draw 是一款开源的AI 3D建模工具,支持将用户在2D画布上绘制的涂鸦草图转化为精美的3D模型。用户能用文本提示或继续绘制迭代优化模型,一键导出为标准格式(.glTF)。
喜欢3D建模的伙伴,如果不会画图也不用担心啦!Vibe Draw可以将你粗糙的草图一键变成3D世界。
同时,也可以带孩子一起绘画,让孩子的涂鸦和各种想象变成现实。
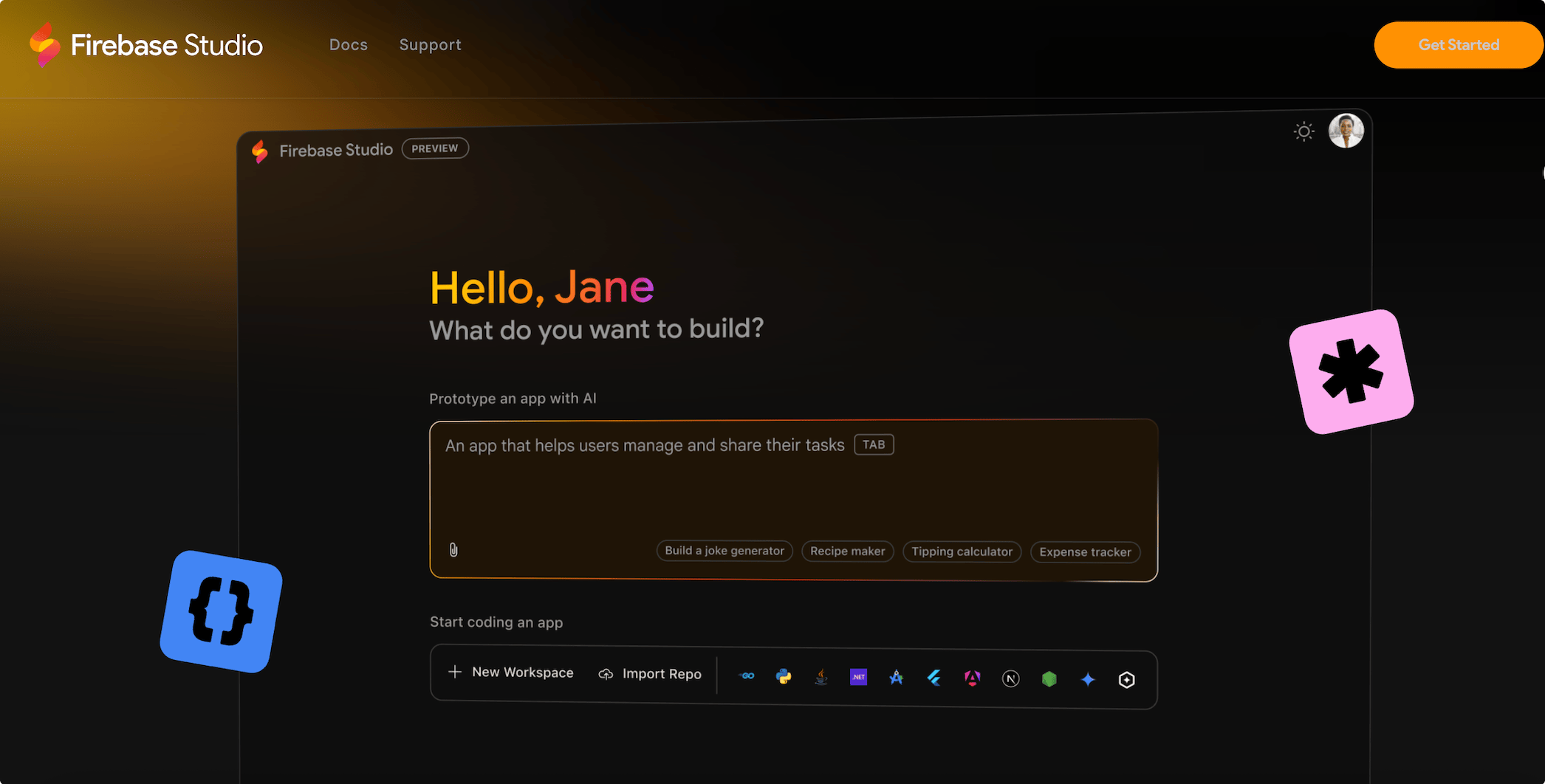
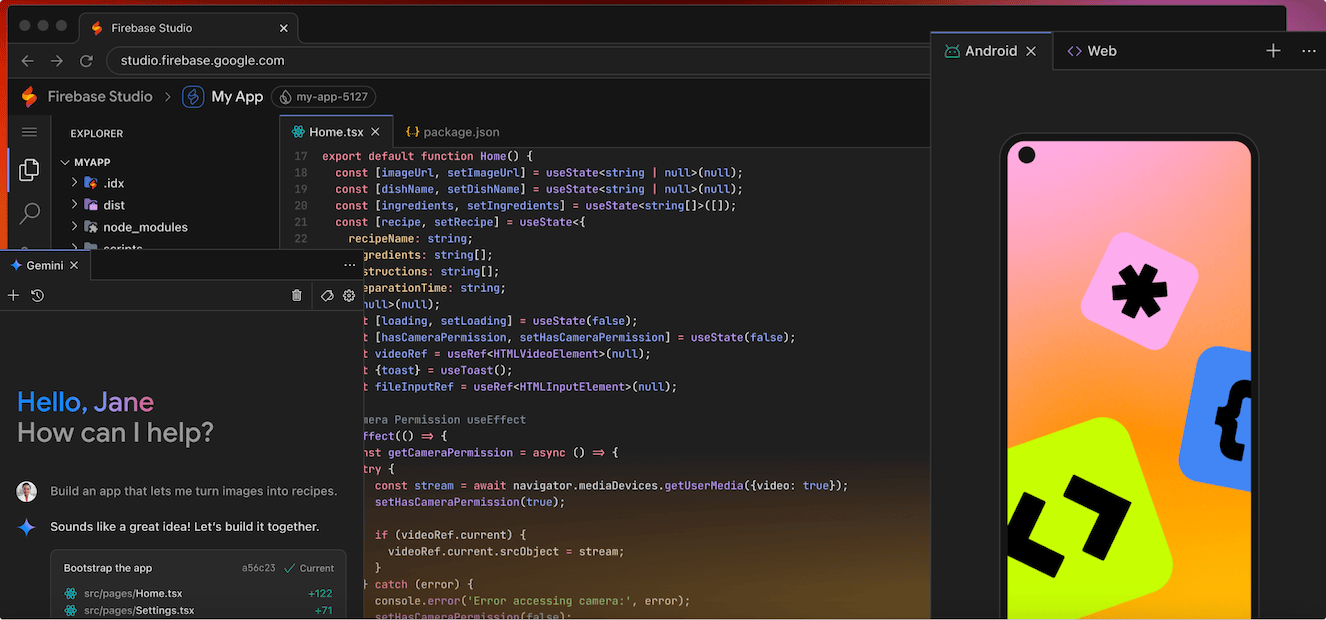
Firebase Studio 是由谷歌推出的云端AI编程工具,将 Project IDX 与 Firebase 中的专用 AI 代理和 Gemini 协助功能整合在一起,从而提供一个可从任何位置访问的协作工作区,其中包含开发应用所需的一切内容。您可以导入现有项目,也可以使用支持各种语言和框架的模板开始创建新项目。
只需要通过文字描述需求或上传图片,AI 即可快速生成完整的应用程序代码。阿喵测试文字输入创建一个搜索页面,AI会提供一个更详细的页面设计,字体、颜色、间距等。能快速展示出设计效果。非常适合开发人员,推荐给喵伙伴,目前完全免费。
支持React、Next.js、Angular、Vue.js、Flutter、Android、Node.js、Java、Python Flash 等多种语言和框架。
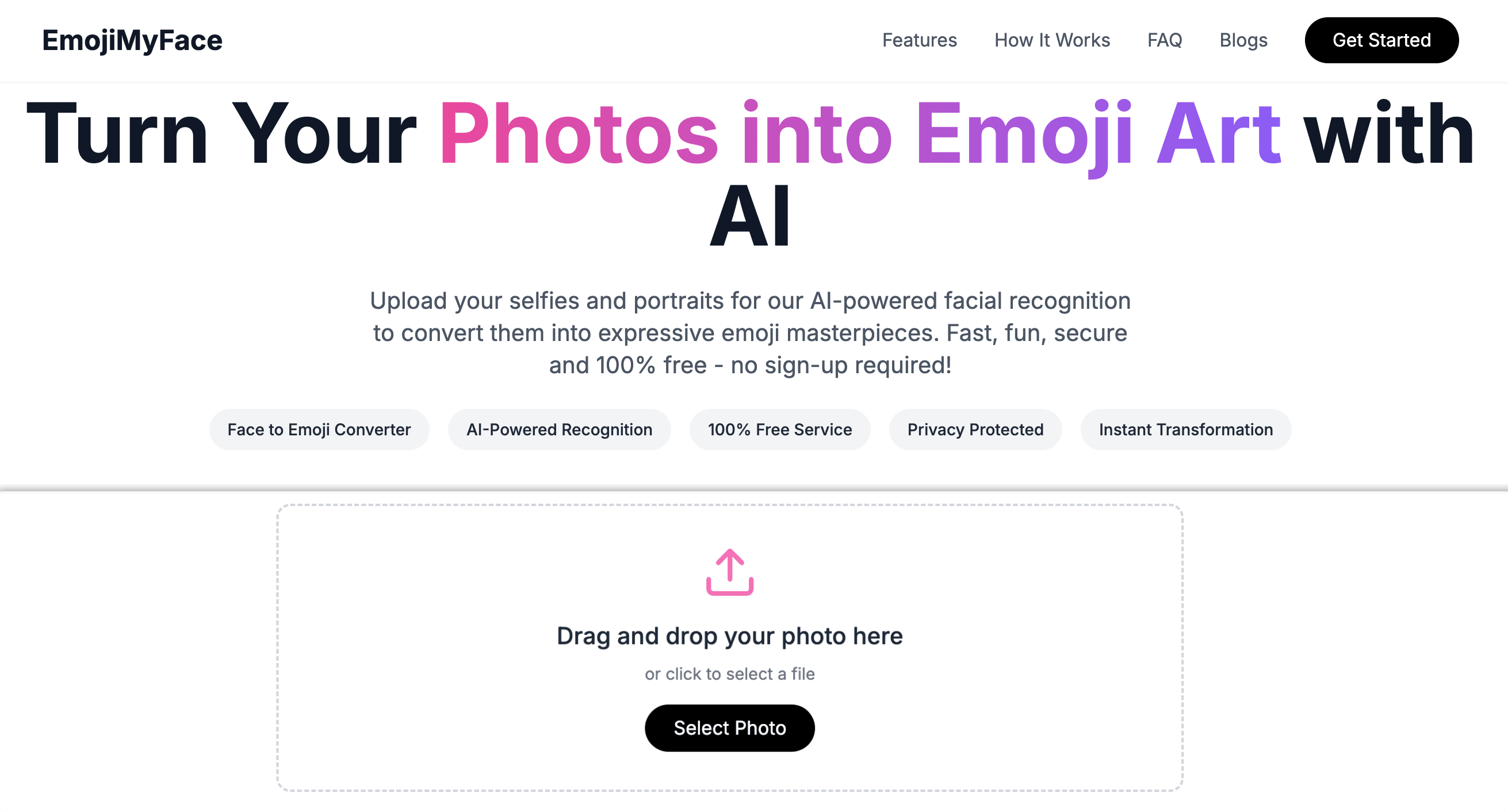
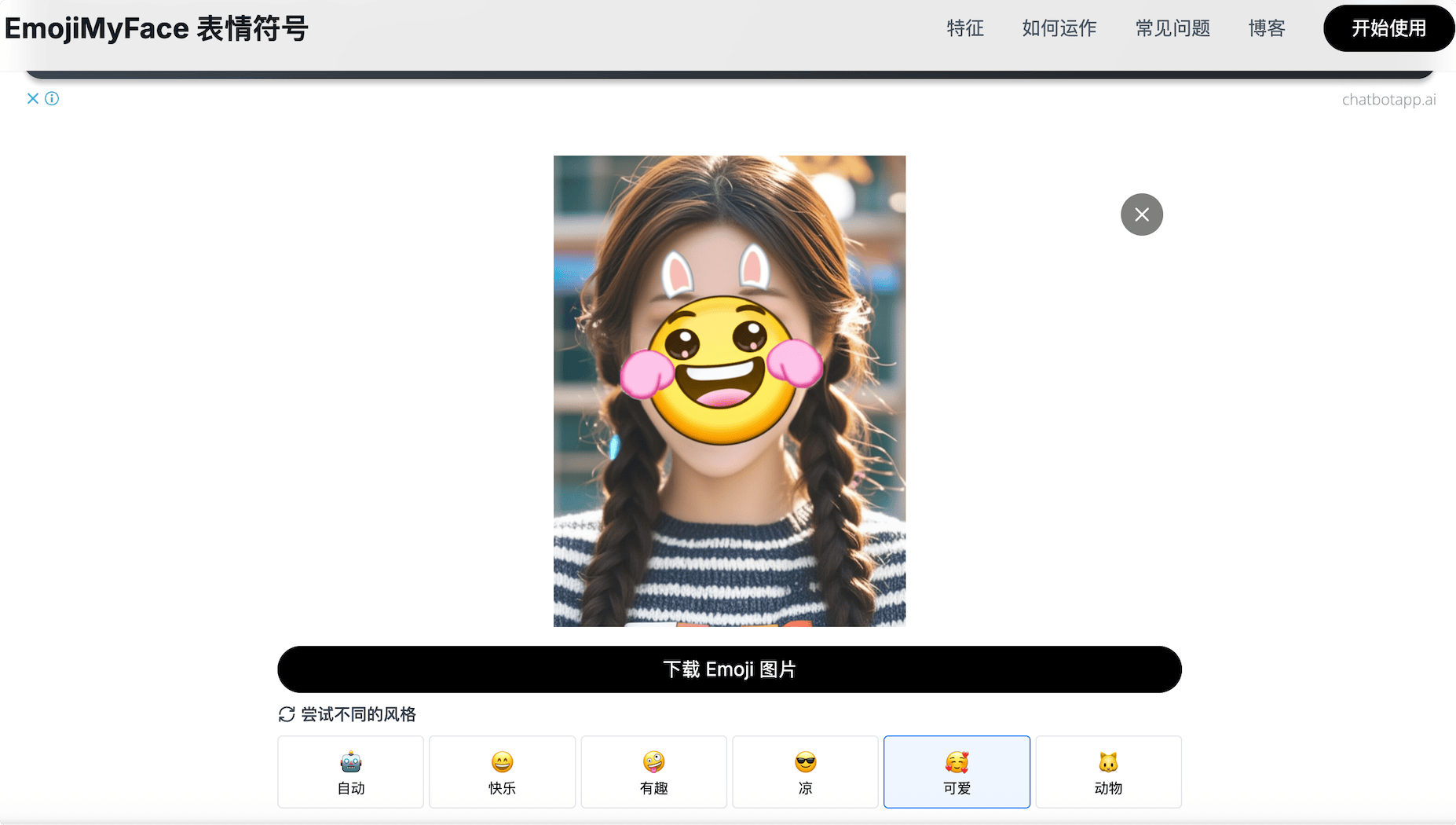
EmojiMyFace 是一个AI 驱动的人脸到表情符号转换工具,可以将照片中的人脸转换为匹配的表情符号。
不是单纯的贴图覆盖,而是会分析照片中的面部表情、特征和情绪,并在保留背景的同时将它们替换为最合适的表情符号,生成自己独有且有趣的Emoji图片。并且支持检测和转换单张照片中的多张面孔 – 非常适合合影!
图片支持JPEG、PNG、WebP 和 GIF(仅限第一帧)格式。每张图像的最大文件大小为 10MB。100% 免费使用,若达到一定限制,等待一小时后再使用即可,无需注册,即时下载,推荐给喵伙伴。

《Hello Ai》采用可视图形化的方式展示Ai的数学,算法,核心机制原理,从0到1,帮助新人更好的入门。为新生构建的可视化的入门AI学习指南,涵盖机器学习、深度学习、强化学习,神经网络,LLM,Ai安全与红队测试
网址:https://dmtomhl.github.io/Google-AI-Red-Team-Tutorial-ZH_CN/

微软又出了一个挺不错的 AI 学习教程 ai-agents-for-beginners,用 10 节课的方式来教会你开发 Agent,教你开始构建 AI 代理所需的一切知识,支持多国语言。当然也支持中文
本课程包含 10 节课,涵盖构建 AI 代理的基础知识。每节课都专注于一个独立主题,因此您可以从任何感兴趣的地方开始!
如果这是您第一次使用生成式 AI 模型进行构建,请查看我们的 生成式 AI 入门课程,该课程包含 21 节课,讲解如何使用生成式 AI。
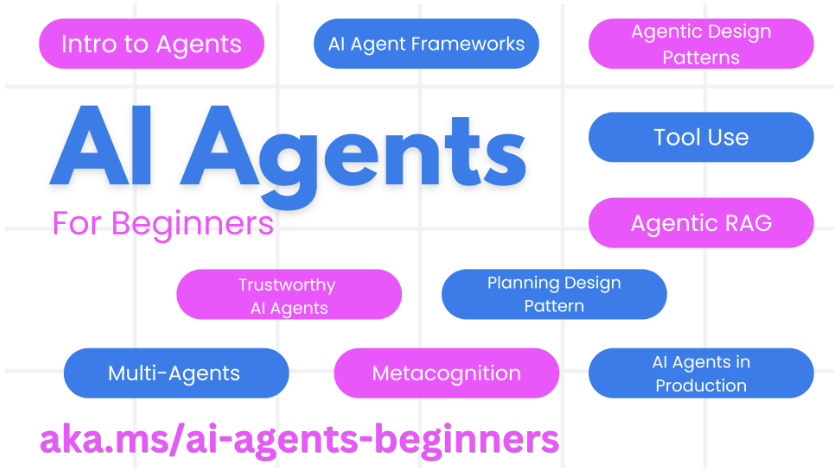
| 课程 | 链接 | 额外学习资源 |
|---|---|---|
| AI 代理简介及应用场景 | AI 代理简介及应用场景 | 了解更多 |
| 探索 Agentic 框架 | Exploring Agentic Frameworks | 了解更多 |
| 理解 Agentic 设计模式 | Understanding Agentic Design Patterns | 了解更多 |
| 工具使用设计模式 | Tool Use Design Pattern | 了解更多 |
| Agentic RAG | Agentic RAG | 了解更多 |
| 构建可信赖的 AI 代理 | Building Trustworthy AI Agents | 了解更多 |
| 规划设计模式 | Planning Design Pattern | 了解更多 |
| 多代理设计模式 | Muilt-Agent Design Pattern | 了解更多 |
| 元认知设计模式 | Metacognition Design Pattern | 了解更多 |
| 生产环境中的 AI 代理 | AI Agents in Production | 了解更多 |
github开源地址(中文):https://github.com/microsoft/ai-agents-for-beginners/blob/main/translations/zh/README.md

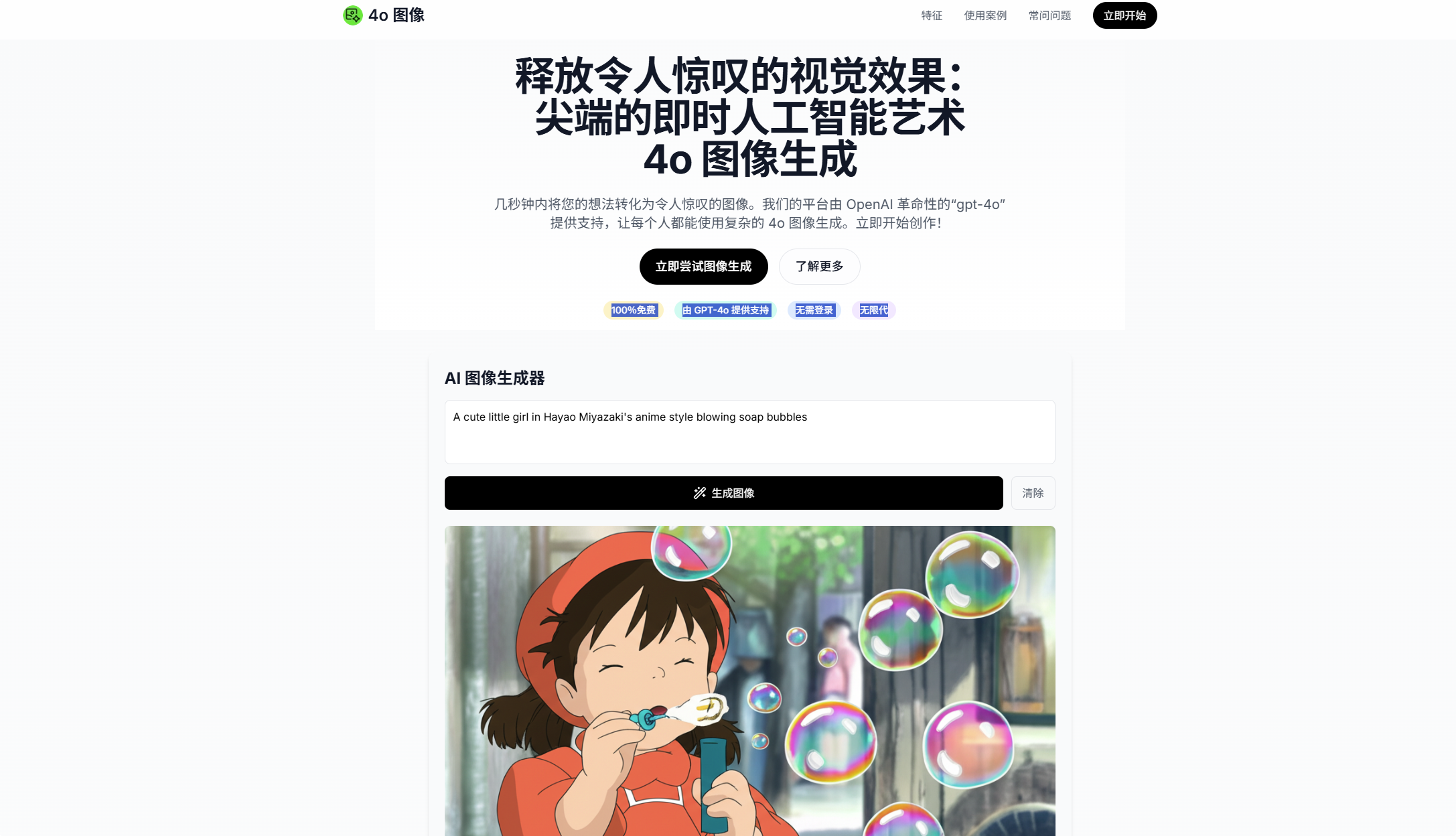
4o Image :基于 GPT-4o 的文生图工具,这个没啥说的,打开即用,无需注册,也没有次数限制,生成速度
几秒钟内将您的想法转化为令人惊叹的图像。我们的平台由 OpenAI 革命性的“gpt-4o”提供支持,让每个人都能使用复杂的 4o 图像生成。立即开始创作!
100%免费由 GPT-4o 提供支持无需登录无限生成,阿喵我测试了下,效果很好,不过需要注意:对中文支持不好,如果输入中文生成的内容可能会奇怪,所以最好是先把描述翻译为英文。生成速度很快!
只需 3 个简单步骤即可创作出令人惊叹的艺术作品
只需输入您要创建的图像的描述即可。您可以根据需要详细或抽象地描述。底层 4o 图像生成引擎依靠创造力蓬勃发展!
点击生成按钮,让我们在“gpt-4o”上运行的强大的 4o 图像生成后端发挥其魔力。通常只需几分钟。
查看生成的图像。挑选您最喜欢的图像,以高分辨率下载,并与全世界分享您的创作。使用 4o 图像生成就是这么简单!
体验 OpenAI 最先进模型的不同之处。得益于新 4o 图像生成功能固有的更快速度、更好的即时理解和更高质量的结果。
无需任何技术技能!我们简洁干净的用户界面让 4o 图像生成的复杂过程对于每个人(从初学者到专业人士)来说都非常简单。
利用“gpt-4o”的效率,以前所未有的速度生成图像。使用我们优化的 4o 图像生成管道,您可以减少等待时间,将更多时间用于创作。
生成适合各种用途的精美高分辨率图像。增强的 4o 图像生成功能可根据您的提示确保获得具有视觉吸引力且连贯的结果。
在利用核心 4o 图像生成能力的同时,我们计划添加易于选择的样式,以帮助您实现完美的外观,从照片般逼真到卡通化。
依靠我们的平台获得一致的性能,并在灵感迸发时获得尖端的 4o 图像生成技术。

PDF craft 可以将 PDF 文件转化为各种其他格式。该项目将专注于扫描书籍的 PDF 文件的处理,目前支持将 PDF 转换为 Markdown 和 EPUB 格式。
它通过逐页读取 PDF,利用 DocLayout-YOLO 和自研算法提取书页中的正文内容,过滤页眉、页脚、脚注、页码等元素。
对于直接扫描生成的中文 PDF 书籍页面,使用 OnnxOCR 进行文字识别,并利用 layoutreader 确定符合人类习惯的阅读顺序。
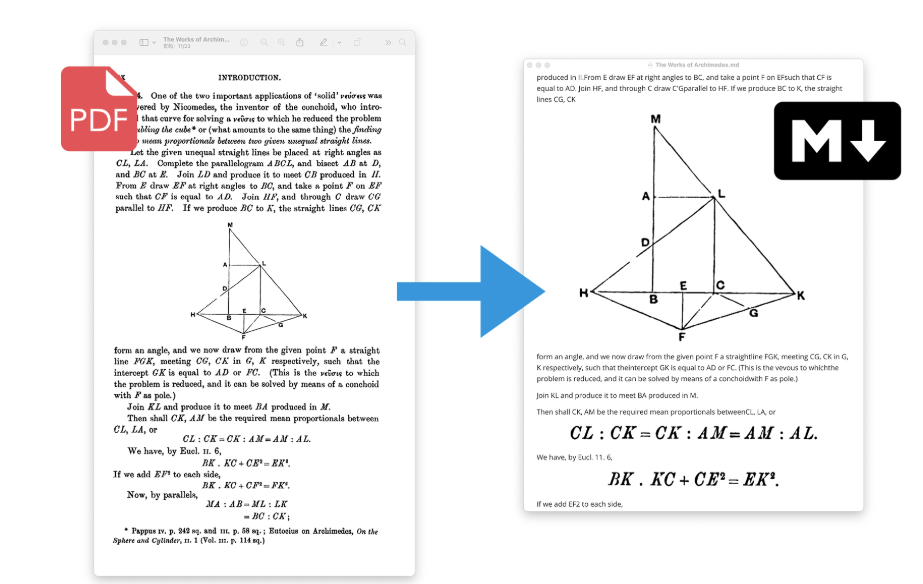
此操作无需调用远程的 LLM,仅凭本地算力(CPU 或显卡)就可完成。第一次调用时会联网下载所需的模型。遇到文档中的插图、表格、公式,会直接截图插入到 MarkDown 文件中。
执行完成后,会在指定的地址生成一个 *.md 文件。若原 PDF 中有插图(或表格、公式),则会在 *.md 同级创建一个 assets 文件夹,以保存图片。而 MarkDown 文件中将以相对地址的形式引用 assets 文件夹中的图片。
转化效果如下。

此操作的前半部分与 PDF 转化 MarkDown(见前章节)相同,将使用 OCR 从 PDF 中扫描并识别文字。因此,也需要先构建 PDFPageExtractor 对象。
之后,需要配置 LLM 对象。建议使用使用 DeepSeek,本库的 Prompt 基于 V3 模型调试。
如上两个对象准备好后,就可以开始扫描并分析 PDF 书籍了。
上述代码注意两个文件夹地址,其一是 output_dir_path,表示扫描和分析的结果(会有多个文件)应该保存在哪个文件夹。该地址应该指向一个空文件夹,若不存在,则会自动创建一个文件夹。
其二是 analysing_dir_path,用来存储分析过程中的中间状态。在扫描和分析成功后,这个文件夹及其内部文件将变得没用(你可以用代码将它们删除)。该地址应该指向一个文件夹,若不存在,则会自动创建一个文件夹。这个文件夹(及其内部文件)可以保存分析进度。若某次分析因为意外而中断,可以通过将 analysing_dir_path 配置到上次被中断而产生的 analysing 文件夹,从而从上次被中断的点恢复并继续分析。特别的,如果你要开始一个全新的任务,请手动删除或清空 analysing_dir_path 文件夹,避免误触发中断恢复功能。
在分析结束后,将 output_dir_path 文件夹地址传给如下代码作为参数,即可最终生成 EPUB 文件。
该步骤会根据之前分析的书本结构,在 EPUB 中分章节,并匹配恰当的目录结构。此外,原本书页底部的注释和引用将以合适的方式呈现在 EPUB 中。


地址(中文):https://github.com/oomol-lab/pdf-craft/blob/main/README_zh-CN.md