Odyssey 是一家 AI 实验室,致力于构建超级想象力,赋能创意人士讲述前所未有的故事。我们最初的旅程始于构建世界模型,以加速电影和游戏的制作——但通过我们的研究,我们现在看到了一种全新娱乐媒介的雏形。我们称之为交互式视频——完全由人工智能实时构想的、既可以观看又可以互动的视频。
它看起来就像你每天观看的视频,但你可以通过引人入胜的方式(使用键盘、手机、控制器,甚至音频)与之互动。可以将其视为全息影像的早期版本。
网站截图

强大的AI推荐
Odyssey 是一家 AI 实验室,致力于构建超级想象力,赋能创意人士讲述前所未有的故事。我们最初的旅程始于构建世界模型,以加速电影和游戏的制作——但通过我们的研究,我们现在看到了一种全新娱乐媒介的雏形。我们称之为交互式视频——完全由人工智能实时构想的、既可以观看又可以互动的视频。
它看起来就像你每天观看的视频,但你可以通过引人入胜的方式(使用键盘、手机、控制器,甚至音频)与之互动。可以将其视为全息影像的早期版本。
Laonv 是一个防情感诈骗AI工具,通过输入感情故事或者聊天记录来判断对方是否在欺骗感情,需要Google账户或者邮箱登录,免费使用,支持输入文字和上传图片。

网友真是什么都能做出来!以前老看到大家玩梗,什么贴吧戒色吧,没想到网友利用AI做了个AI戒色助理:QuitPorn AI是一个创新平台,利用人工智能技术帮助用户戒除手淫行为、克服色情成瘾,并通过戒色方案减少强迫性行为。
记录你克服色情成瘾的康复历程,通过每日评估了解和识别你的触发因素和风险
提供基础的免费戒色服务,允许用户使用核心功能。高级戒色功能需要订阅,可获得更专业的康复工具和个性化支持
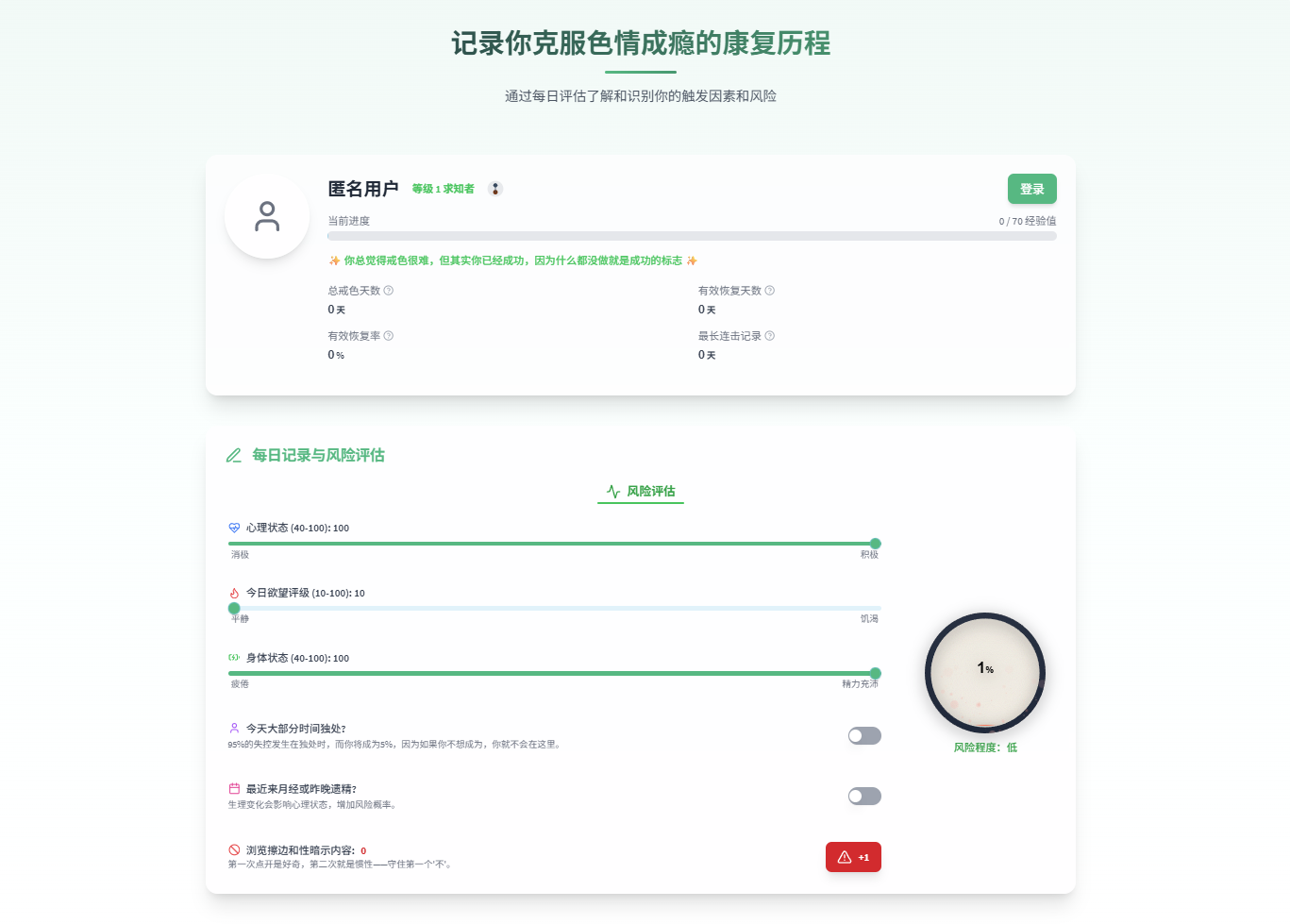
戒色AI辅导:获得针对戒色困扰的个性化策略和专业支持。
戒除根源分析:准确识别影响戒色的潜在原因,分析戒色过程中的误区、冲动控制难题,以及不当应对机制。明确你的关键挑战。
康复社区支持:加入我们独特的戒色社区,专注于长期康复而非短期戒断。分享戒色经验和控制技巧,帮助每个人尽快恢复。
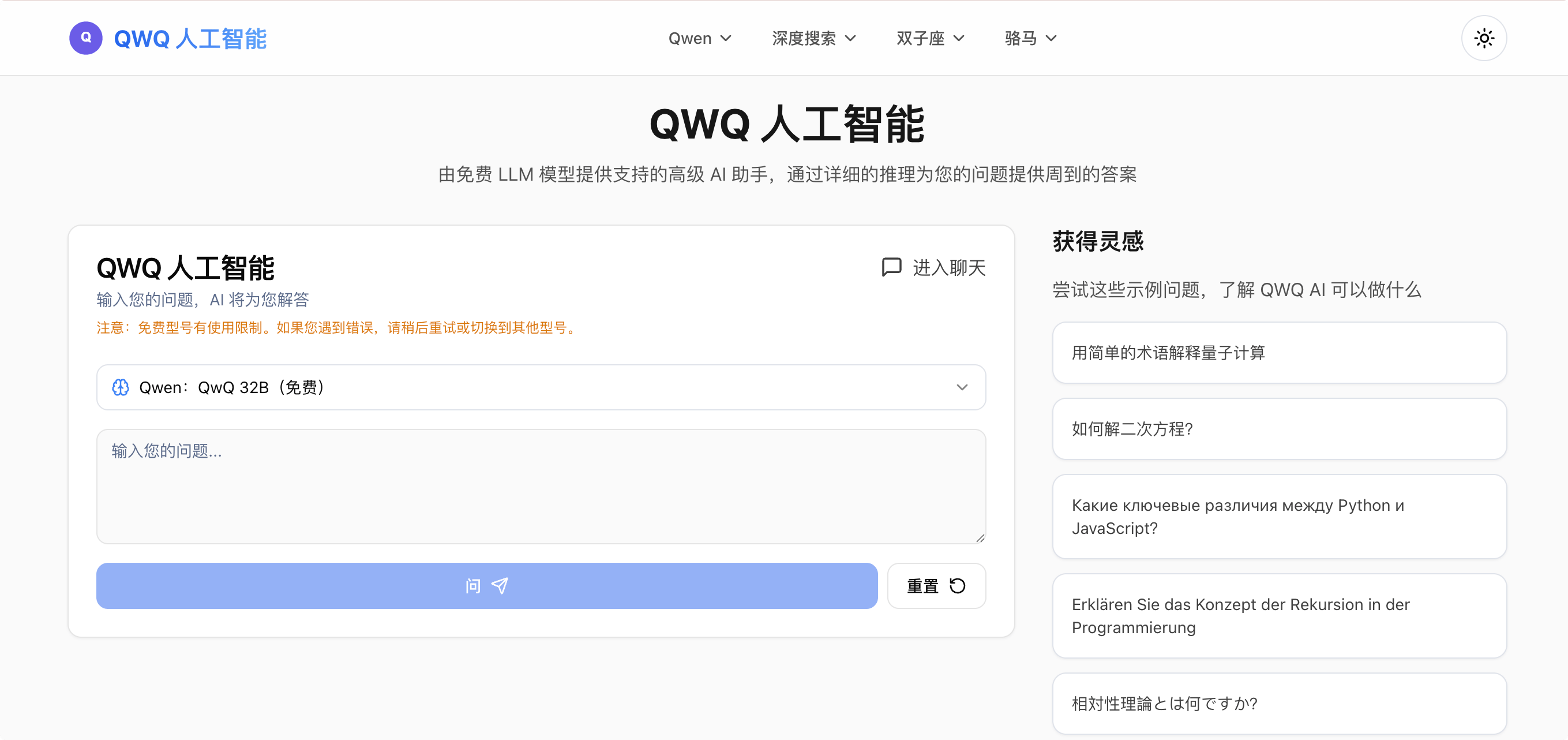
现在已经有了很多AI问答工具,今天给大家推荐一个即可以问答又可以聊天的AI工具–QWQ AI。帮助你在工作和学习中,获取灵感,快速解决问题。
QWQ AI,是由免费 LLM 模型提供支持的高级 AI 助手,通过详细的推理为您的问题提供周到的答案。无需登录即可使用,提供两种主要的交互模式:Q&A 模式和聊天模式。Q&A 模式适用于单个查询,而聊天模式支持连续对话,可任意选择,支持中文、英文、俄文、日语等多种语言。
魔法AI绘画,一个基于 Next.js 开发的 AI 绘画应用,支持多种 AI 模型(Sora、DALL-E、GPT等)及自定义模型添加,提供文生图和图生图功能,支持多图参考和区域编辑,所有数据和API密钥本地存储,保障隐私安全,支持网页版及桌面应用打包,跨平台使用。
需要配置GPT、DALL-E、Sora等模型的key,方可使用。
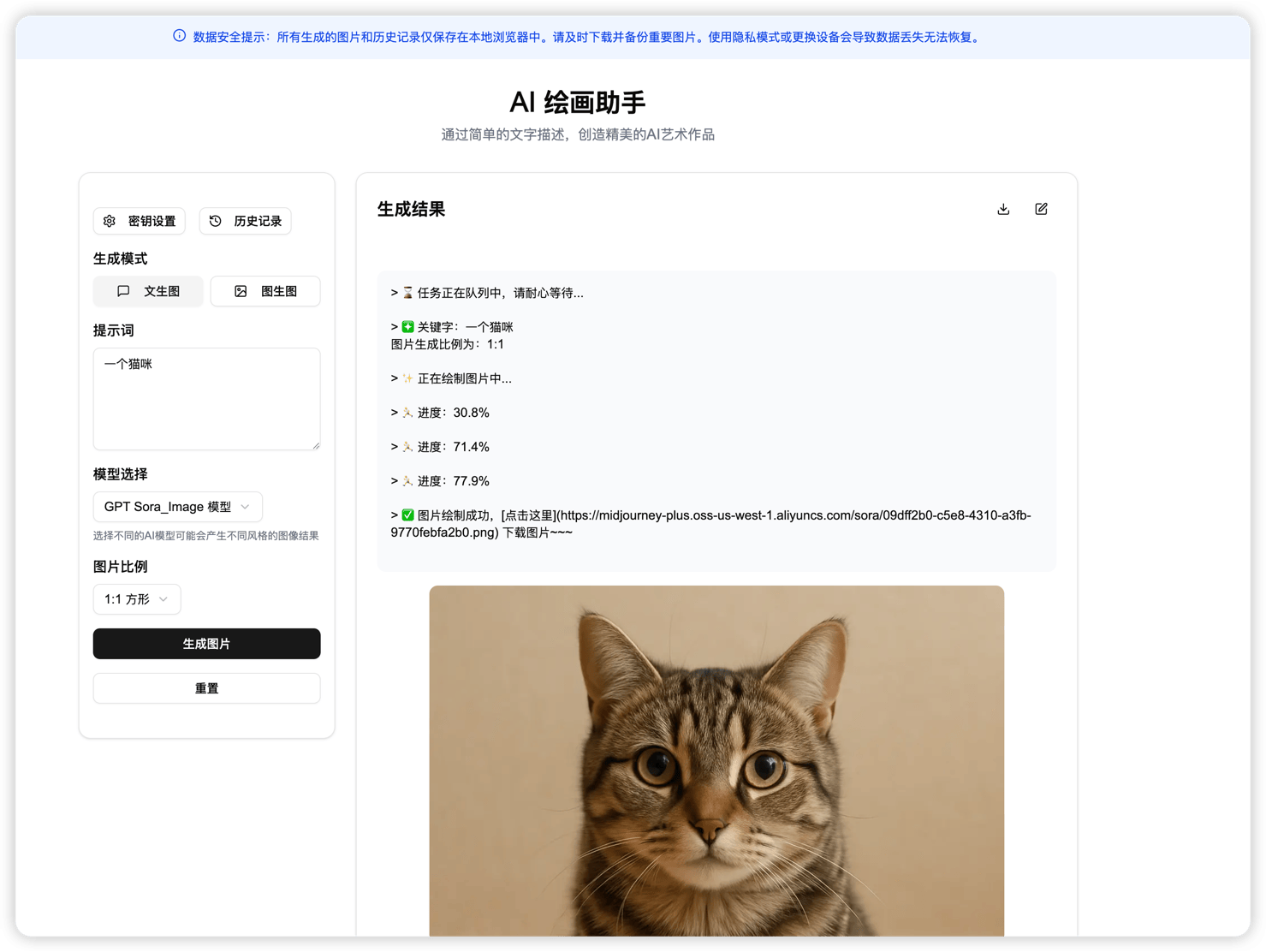
AI智能进入医疗行业了,阿喵发现一个新项目,使用AI辅助眼科医生治疗。
OcuAssist是一款基于Tauri框架开发的AI辅助眼底多模态诊断软件,集成了AI辅助探测、AI辅助诊断和AI对话等功能,为眼科医生提供智能化的诊断支持。
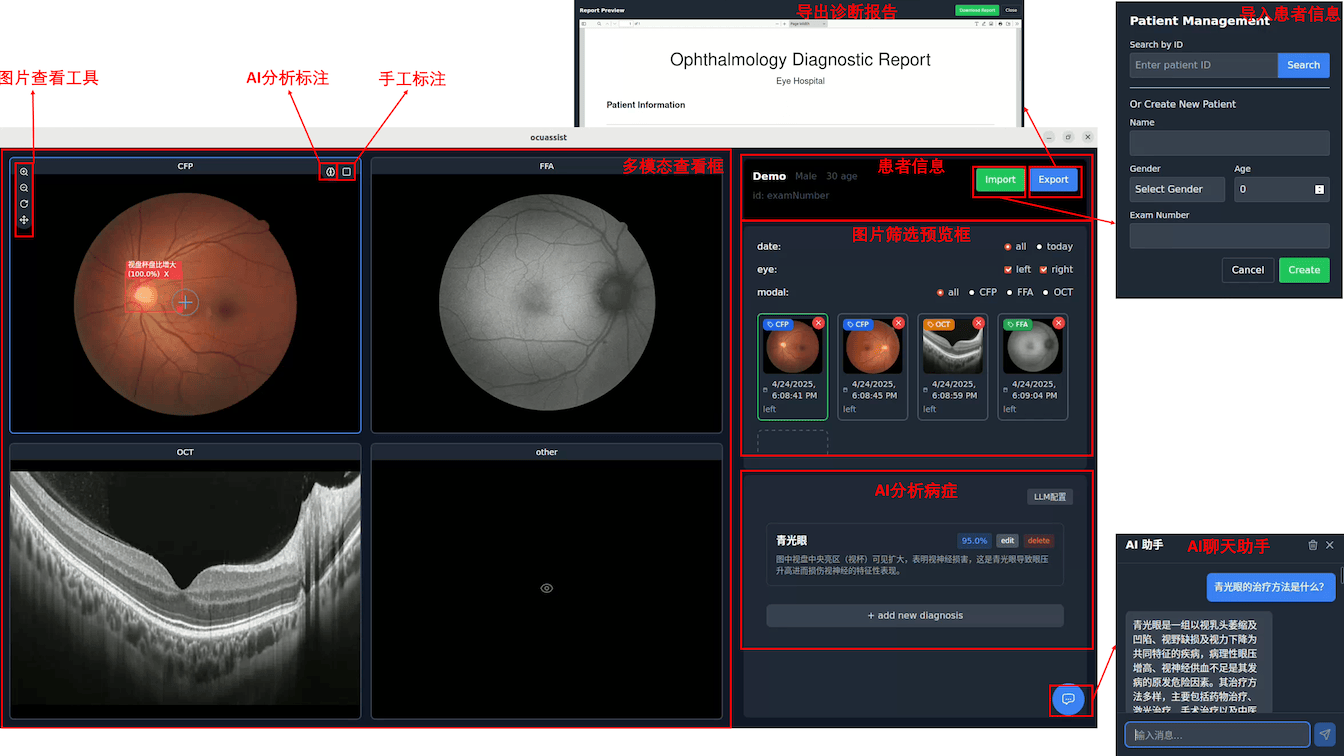
PandaWiki 是一款 AI 驱动的开源知识库搭建系统,借助大模型的力量为你提供 AI 创作、AI 问答、AI 搜索等能力,让你快速拥有智能化的 产品文档、FAQ、博客系统。
PandaWiki:内置强大的 RAG 能力,可用于智能客服、教育培训、法律咨询、医疗咨询等问答系统。
极简操作,零门槛上手
深度封装复杂技术,无需专业知识,轻松驾驭 AI 知识库,告别繁琐配置,让知识管理变得简单直观
无缝对接,打破知识孤岛
支持对接各类第三方知识库与 wiki 应用,一键导入海量文档,快速整合分散知识资源,构建统一知识管理中枢
灵活集成,赋能多元场景
可与微信机器人、钉钉机器人、网页挂件等第三方业务系统快速集成,轻松嵌入现有工作流,实现知识高效流转与即时应用
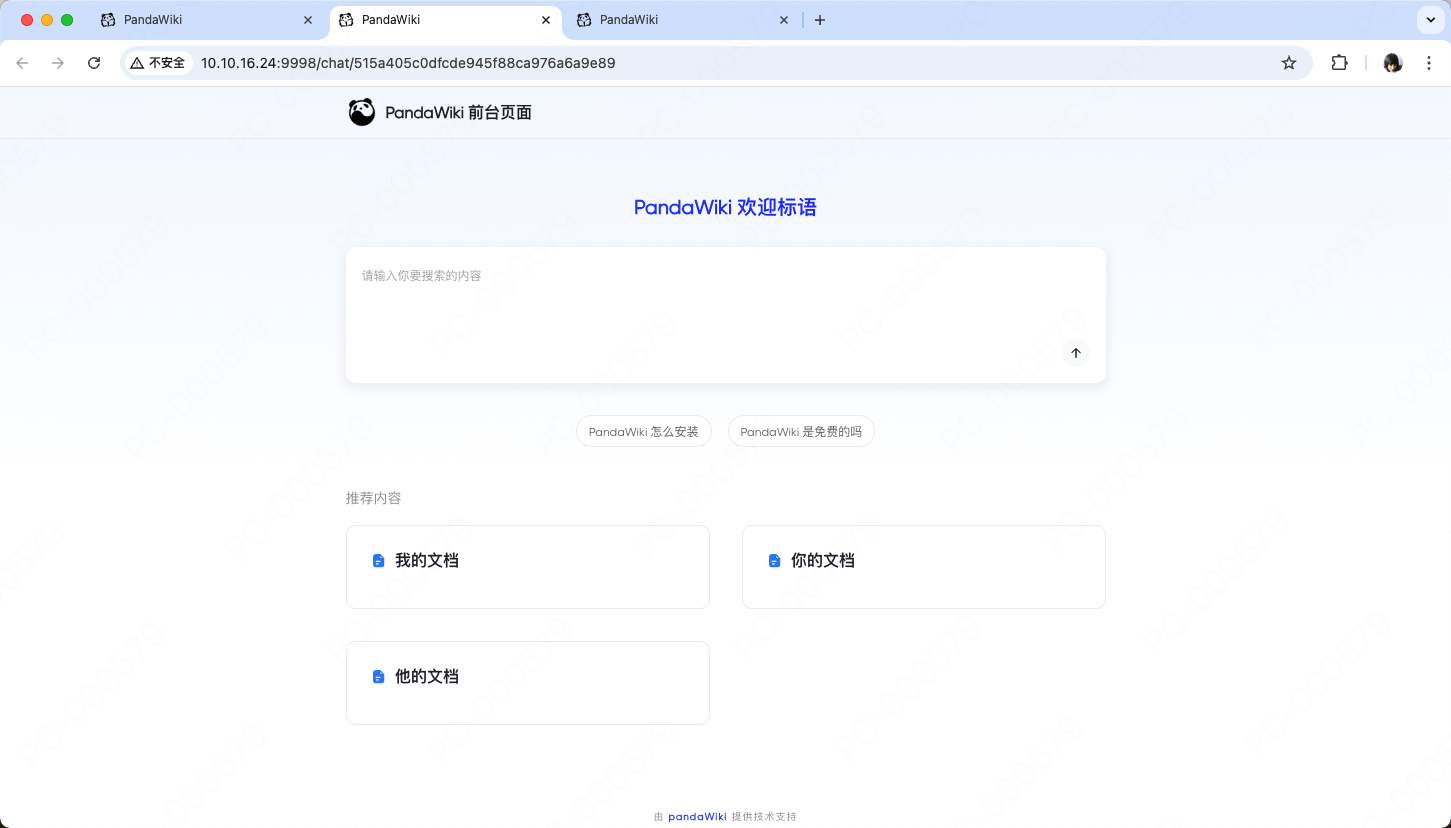
通过第三方来源导入内容:根据网页 URL 导入、通过网站 Sitemap 导入、通过 RSS 订阅、通过离线文件导入等。
AI 驱动智能化:AI 辅助创作、AI 辅助问答、AI 辅助搜索。
强大的富文本编辑能力:兼容 Markdown 和 HTML,支持导出为 word、pdf、markdown 等多种格式。
轻松与第三方应用进行集成:支持做成网页挂件挂在其他网站上,支持做成钉钉、飞书、企业微信等聊天机器人。
安装 PandaWiki 前请确保你的系统环境符合以下要求
使用 root 权限执行以下命令进行安装
bash -c "$(curl -fsSLk https://release.baizhi.cloud/pandawiki/manager.sh)"
安装完成后,控制台默认监听在 9998 端口,使用浏览器访问 http://127.0.0.1:9998 就能看到登录页面。
默认账号密码会在安装时随机生成,请查看安装命令的输出内容。
在 PandaWiki 控制台的右上角点击 系统配置 按钮,在弹出窗口中配置供 PandaWiki 使用的大模型。
PandaWiki 目前支持接入以下大模型
- DeepSeek:参考文档 DeepSeek
- OpenAI:ChatGPT 所使用的大模型,参考文档 OpenAI
- Ollama:Ollama 通常是本地部署的大模型,参考文档 Ollama
- 硅基流动:参考文档 SiliconFlow
- 月之暗面:Kimi 所使用的模型,参考文档 Moonshot
- 其他:其他兼容 OpenAI 模型接口的 API
完成以上配置后你就可以开始 PandaWiki 了,开始创建文档,并使用 AI 问答功能吧。
内容创作者,当发送视频或者文字需要配音的时候,经常苦于音乐版权问题,甚至在不知情的情况下使用的有版权的音乐,造成内容违规。阿喵想着那可以试试自己创造音乐啦!
AI Song Maker,一个在线AI音乐生成器,可以选择文本转歌曲和歌词转歌曲,选择音乐风格,说唱、摇滚、流行等,点击生成音乐即可。
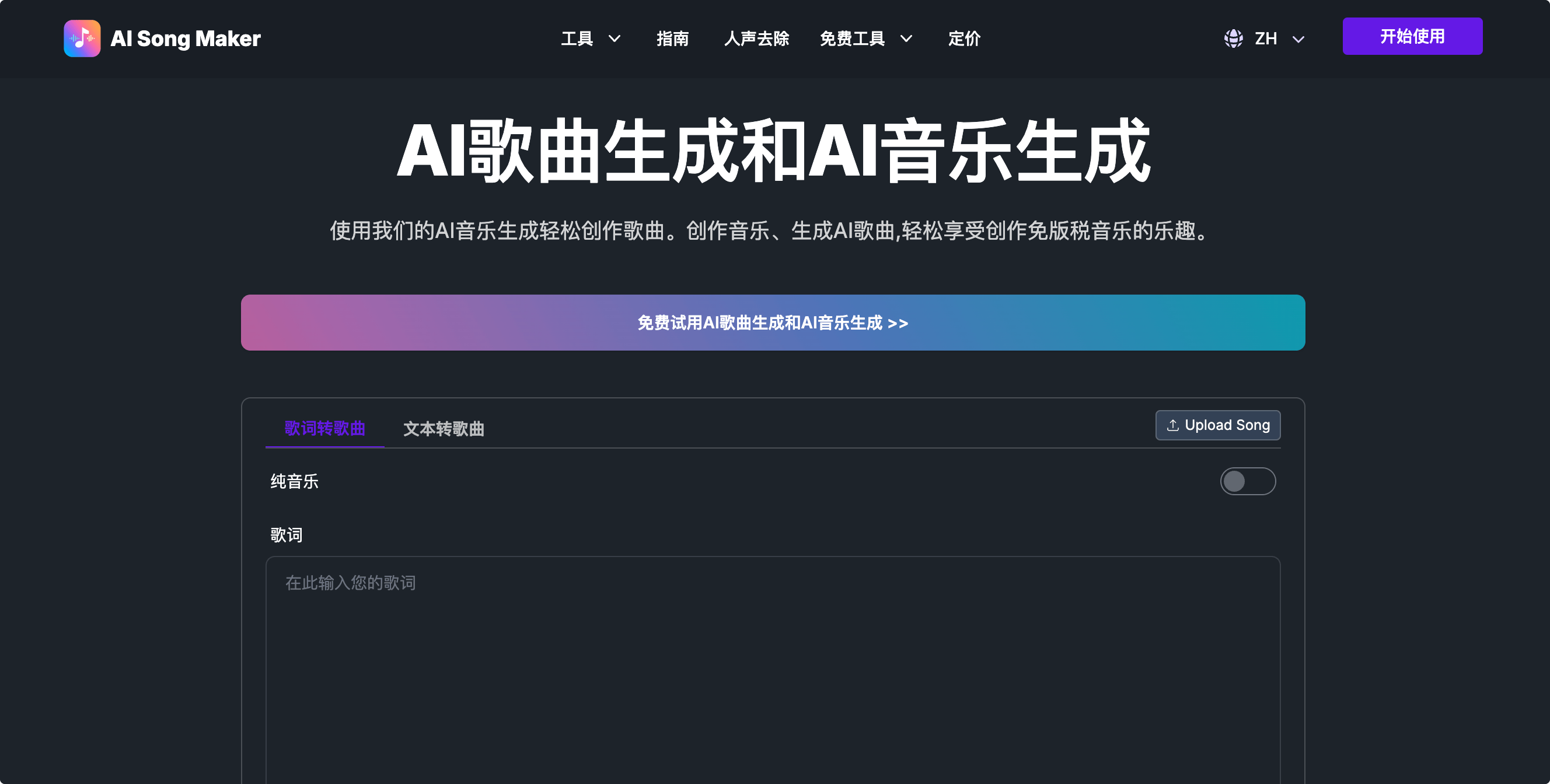
首先选择是要从文本生成歌曲还是从歌词生成歌曲,或选择纯音乐曲目。我们的AI音乐生成器会适应您的创作需求。
探索说唱、摇滚、流行等不同风格,或自定义男/女声和节奏。然后添加独特的标题来个性化您的歌曲并使其脱颖而出。
使用AI音乐生成生成您的音乐,然后立即下载免版税音乐或通过平台与您的听众分享。
之前有AI工具支持写小说,现在的AI工具不仅可以写小说,还能提取小说片段生成视频。
TaleStreamAI,专注于自动化将 AI 生成的小说片段转化为引人入胜的视频内容以进行社交媒体分享的过程。工作流程无缝集成了最新的 AI 技术,以视觉上引人入胜的格式使虚构故事栩栩如生。推荐!
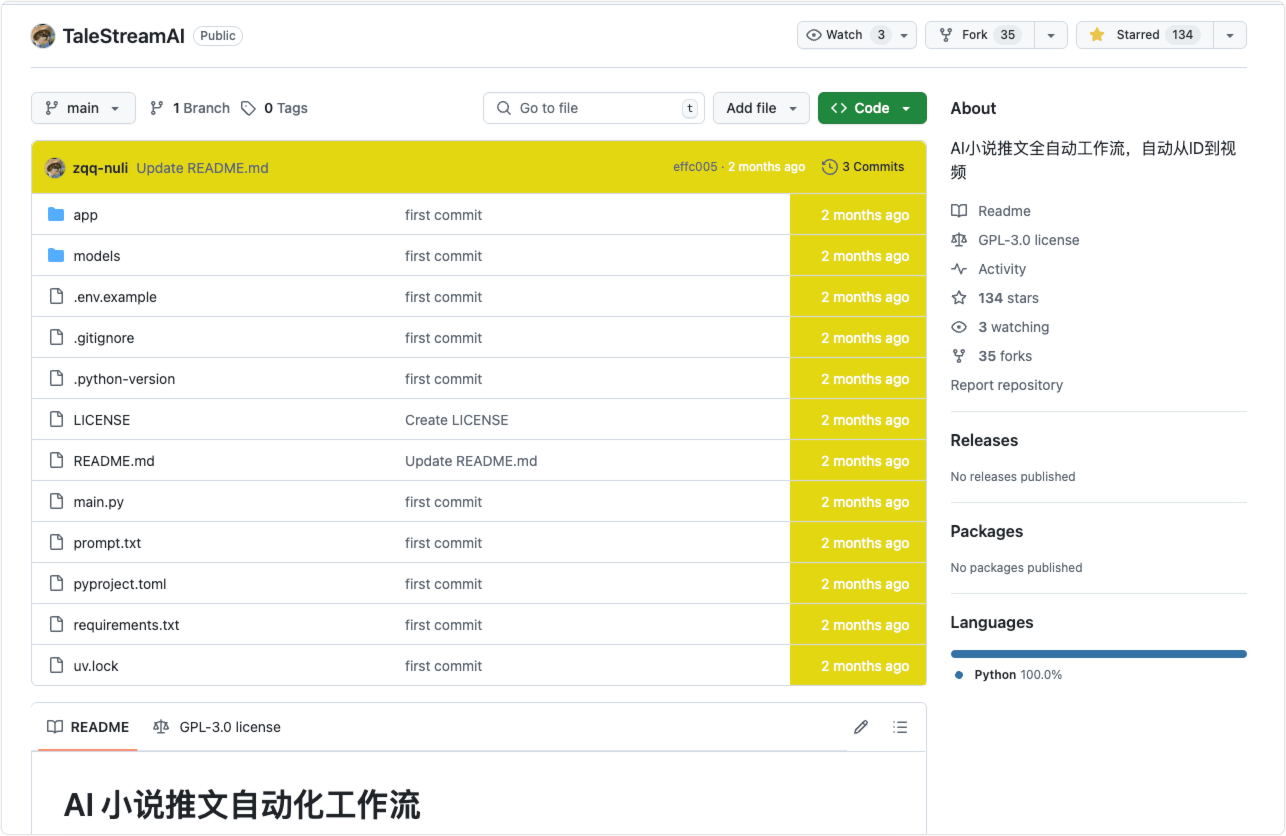
全自动工作流程: TaleStreamAI 通过利用 AI 算法简化整个过程,消除了创建视频内容所涉及的体力劳动。
AI 小说推文提取:系统自动提取 AI 模型生成的小说推文,作为视频内容的基础。
视频创作: 利用 AI 的力量,TaleStreamAI 将新颖的片段转换为具有视觉吸引力的视频,以便在各种社交媒体平台上分享。
效率和创新:通过将 AI 功能与讲故事相结合,TaleStreamAI 突破了内容创建和分发的界限。
项目流程
| 文件名 | 功能 | 模型/库 |
|---|---|---|
| main.py | 获取书籍内容 | 无 |
| board.py | 生成章节分镜 | gemini-2.0-flash |
| prompt.py | 润色分镜提示词 | deepseek-v3 |
| image.py | 生成图片 | 秋葉 aaaki forge 版 |
| audio.py | 生成音频 | CosyVoice2-0.5B:benjamin |
| tts.py | 生成字幕 | 本地运行 whisper |
| video.py | 生成视频 | ffmpeg-gpu 加速版 |
| video_end.py | 生成完整视频 | ffmpeg-gpu 加速版 |
本项目使用的是
uv来管理依赖,建议 python 版本>=3.10
uvpip install uv
uv venv --python 3.12
.\.venv\Scripts\activate
uv add -r requirements.txt
uv pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
可以通过nvidia-smi来查询你的显卡支持的最高cuda版本
nvidia-smi +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 560.94 Driver Version: 560.94 CUDA Version: 12.6 | |-----------------------------------------+------------------------+----------------------+ | GPU Name Driver-Model | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA GeForce RTX 4070 Ti WDDM | 00000000:01:00.0 On | N/A | | 0% 28C P8 4W / 285W | 2157MiB / 12282MiB | 2% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+
通过 nvcc 来查询你电脑已安装的cuda版本
其实是你环境变量中配置的版本而已,一个电脑上可以安装多个 cuda
nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2022 NVIDIA Corporation Built on Wed_Sep_21_10:41:10_Pacific_Daylight_Time_2022 Cuda compilation tools, release 11.8, V11.8.89 Build cuda_11.8.r11.8/compiler.31833905_0
复制 .env.example 文件,改名为 .env
配置其缺少的 APIKey
其中 AUDIO_API_KEY 是可以支持多 Key 轮询的,用,分割
(做到这一步我才意识到可以多 Key 支持高并发 😂 如果需 Gemini 需要高并发的话,可能需要手动去 copy 多 key 的处理的代码到board.py中了)
配置起点达人中心的 Cookie 用来抓取小说 起点达人中心
安装ffmpeg最好安装GPU加速版,否则生成的很慢(好像新一点的版本都已经支持gpu加速了) Github
使用 ffmpeg -hwaccels 来列出硬件加速选项
Hardware acceleration methods: cuda vaapi dxva2 qsv d3d11va opencl vulkan
我是直接按照项目流程来逐个运行文件的
uv run app/main.py # 获取小说内容 uv run board.py # 生成分镜 uv run prompt.py # 优化提示词 uv run image.py # 生成图片 uv run audio.py # 合成音频 uv run tts.py # 生成字幕 uv run video.py # 制作分镜视频 uv run video_end.py # 最终合成
如果你想要直接运行 也可以直接运行 main.py
uv run main.py
Whisper 模型规格
| 模型规格 | 参数量 | 最低显存要求 |
|---|---|---|
| Tiny | 39M | ~1GB |
| Base | 74M | ~1GB |
| Small | 244M | ~2GB |
| Medium | 769M | ~5GB |
| Large | 1550M | ~10GB |
| Large-v2 | 1550M | ~10GB |
| Large-v3 | 1550M | ~10GB |
import torch
from transformers import WhisperProcessor, WhisperForConditionalGeneration
# 选择适合您显存的模型大小,例如"medium"
model_id = "openai/whisper-medium"
# 启用半精度以节省显存
processor = WhisperProcessor.from_pretrained(model_id)
model = WhisperForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="auto"
)
# 确保模型在GPU上运行
device = "cuda" if torch.cuda.is_available() else "cpu"
model = model.to(device)
在人工智能飞速发展的今天,视频内容的创作与编辑正经历着一场深刻的变革。传统的视频制作流程往往耗时耗力,对专业技能和设备都有较高要求。而 FramePack AI 项目的出现,为我们提供了一种全新的可能性——利用最先进的人工智能技术,赋能每一位用户,轻松创作出高质量、长篇幅的视频内容。它采用逐帧预测和上下文压缩技术,使得生成过程显存占用低、速度快,即使在显存只有 6GB 的设备上也能流畅运行。可自行部署使用
支持 30 帧每秒的视频输出,集成 Gradio 界面,提供实时预览和交互式操作体验,支持 RTX 30/40/50 系列显卡和 FP16/BF16 格式
FramePack AI 是一个致力于利用人工智能技术创建高质量、长篇幅视频的项目。使用先进的AI技术将您的照片变成独特的视频。每个视频都是根据您的图像中的人物个性精心设计的,具有特效和过渡效果
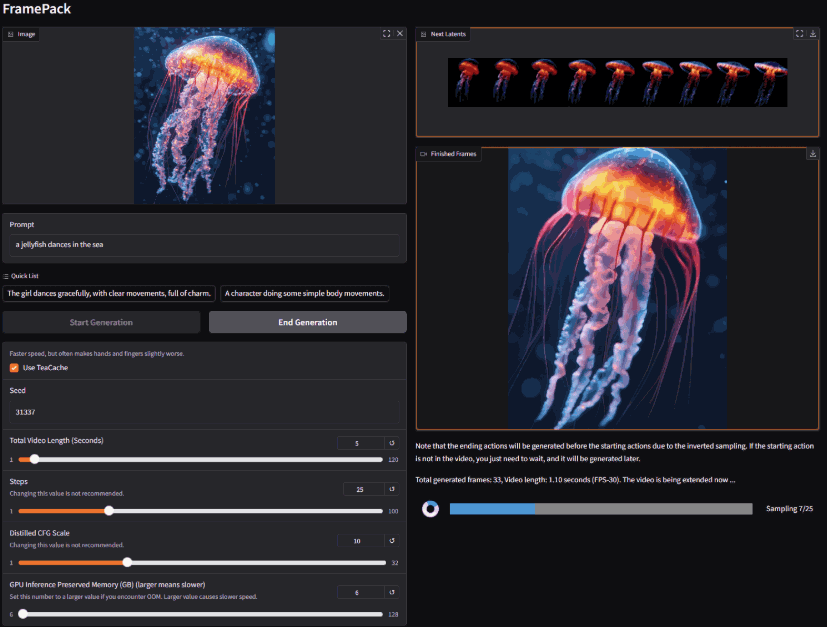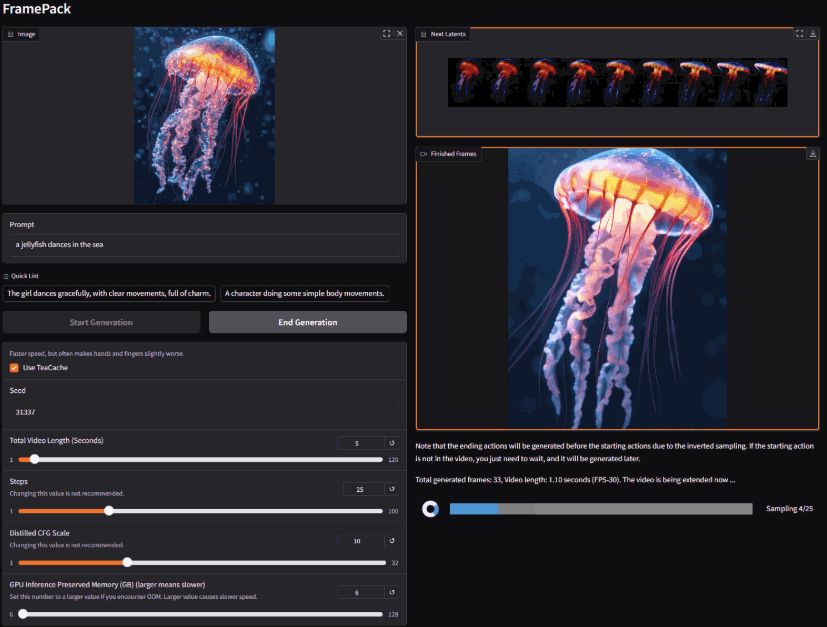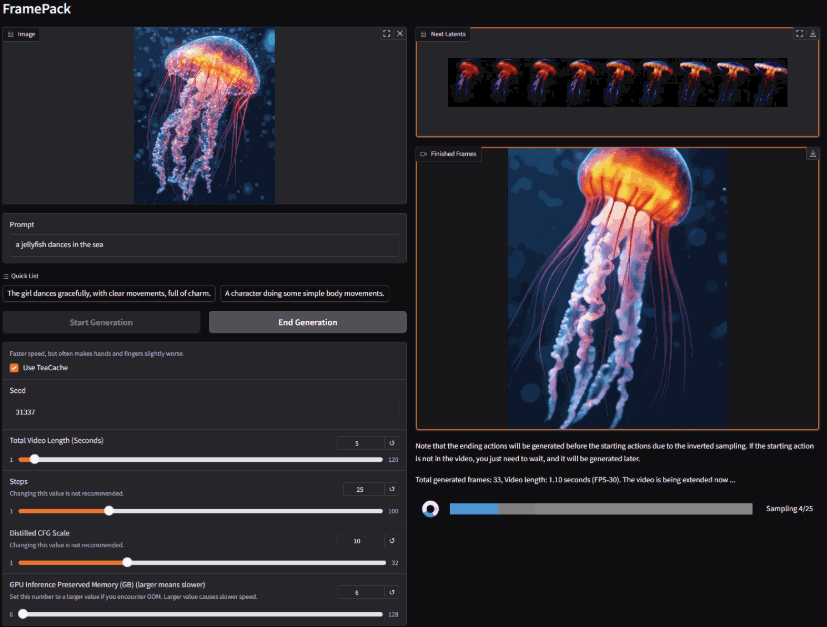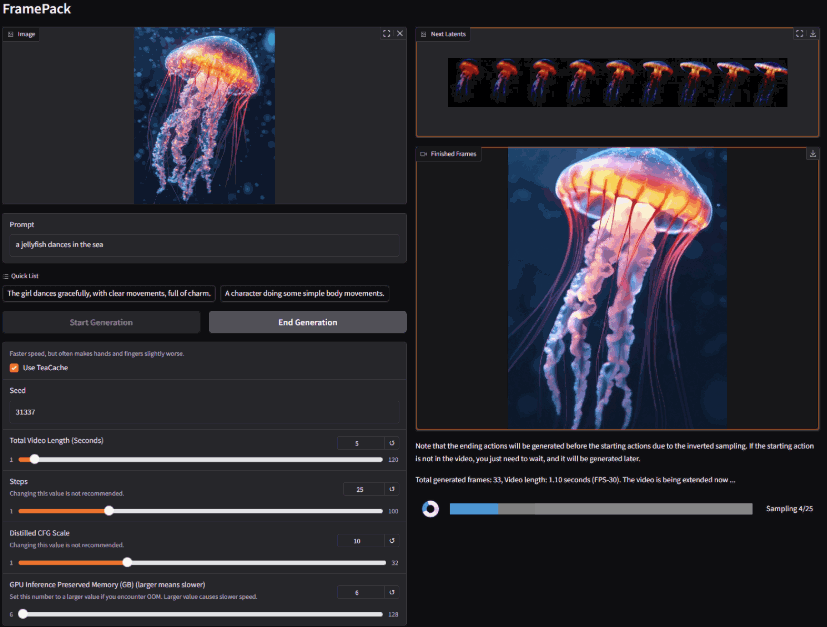
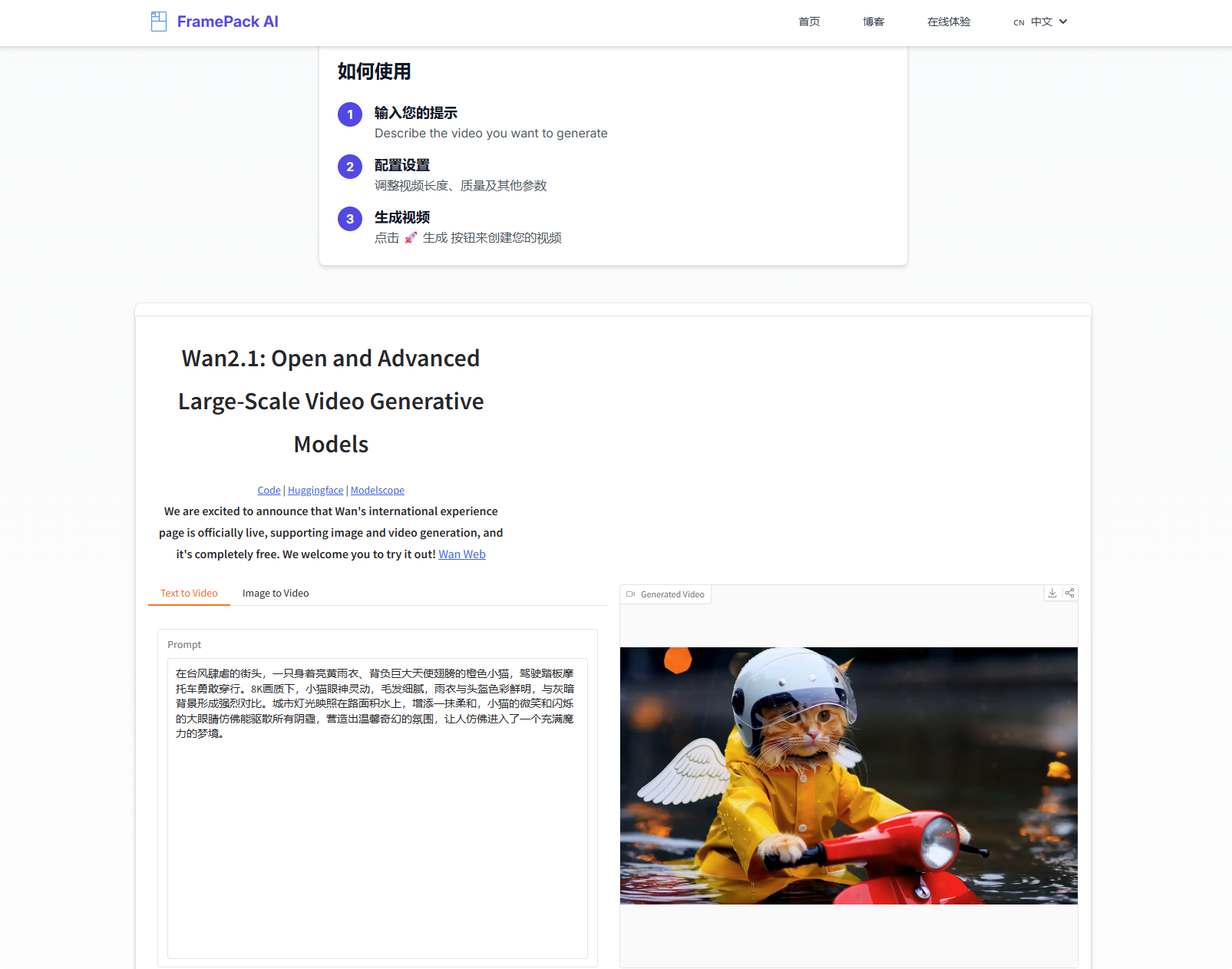
要求:
要使用 13B 模型以 30fps(1800 帧)的速度生成 1 分钟(60 秒之前)的视频,最低需要 6GB 的 GPU 内存。(没错,是 6GB,没错。笔记本电脑的 GPU 就可以了。)
关于速度,在我的 RTX 4090 台式机上,它的生成速度为 2.5 秒/帧(未优化)或 1.5 秒/帧(teacache)。在我的笔记本电脑上,例如 3070ti 笔记本电脑或 3060 笔记本电脑,速度大约慢 4 到 8 倍
具体看github上的介绍:https://github.com/lllyasviel/FramePack?tab=readme-ov-file#installation
官网地址:https://framepack.net/zh/