项目介绍
Z-Image 是一款功能强大且高效的图像生成模型,拥有60 亿个参数。目前有三种变体:
- 🚀 Z-Image-Turbo – Z-Image 的精简版,仅需8 次函数评估 (NFE),即可达到甚至超越领先竞争对手的性能。它在企业级 H800 GPU 上可实现⚡️亚秒级推理延迟⚡️,并能轻松适配16G 显存的消费级设备。它在照片级图像生成、双语文本渲染(中英文)以及强大的指令执行能力方面表现卓越。
- 🧱 Z-Image-Base – 未经精简的基础模型。通过发布此版本,我们旨在充分释放社区驱动的微调和自定义开发的潜力。
- ✍️ Z-Image-Edit – Z-Image 的一个衍生版本,专为图像编辑任务而优化。它支持创意图像到图像的生成,并具备强大的指令跟随功能,允许根据自然语言提示进行精确编辑。
展示
📸照片级真实感:Z-Image-Turbo能够生成逼真的照片级图像,同时保持优异的美学品质。

📖精准的双语文本渲染:Z-Image-Turbo擅长精准渲染复杂的中文和英文文本。

💡 提示增强和推理:提示增强器赋予模型推理能力,使其能够超越表面描述并挖掘潜在的世界知识。

🧠创意图像编辑:Z-Image-Edit对双语编辑指令有很强的理解力,能够进行富有想象力和灵活的图像变换。

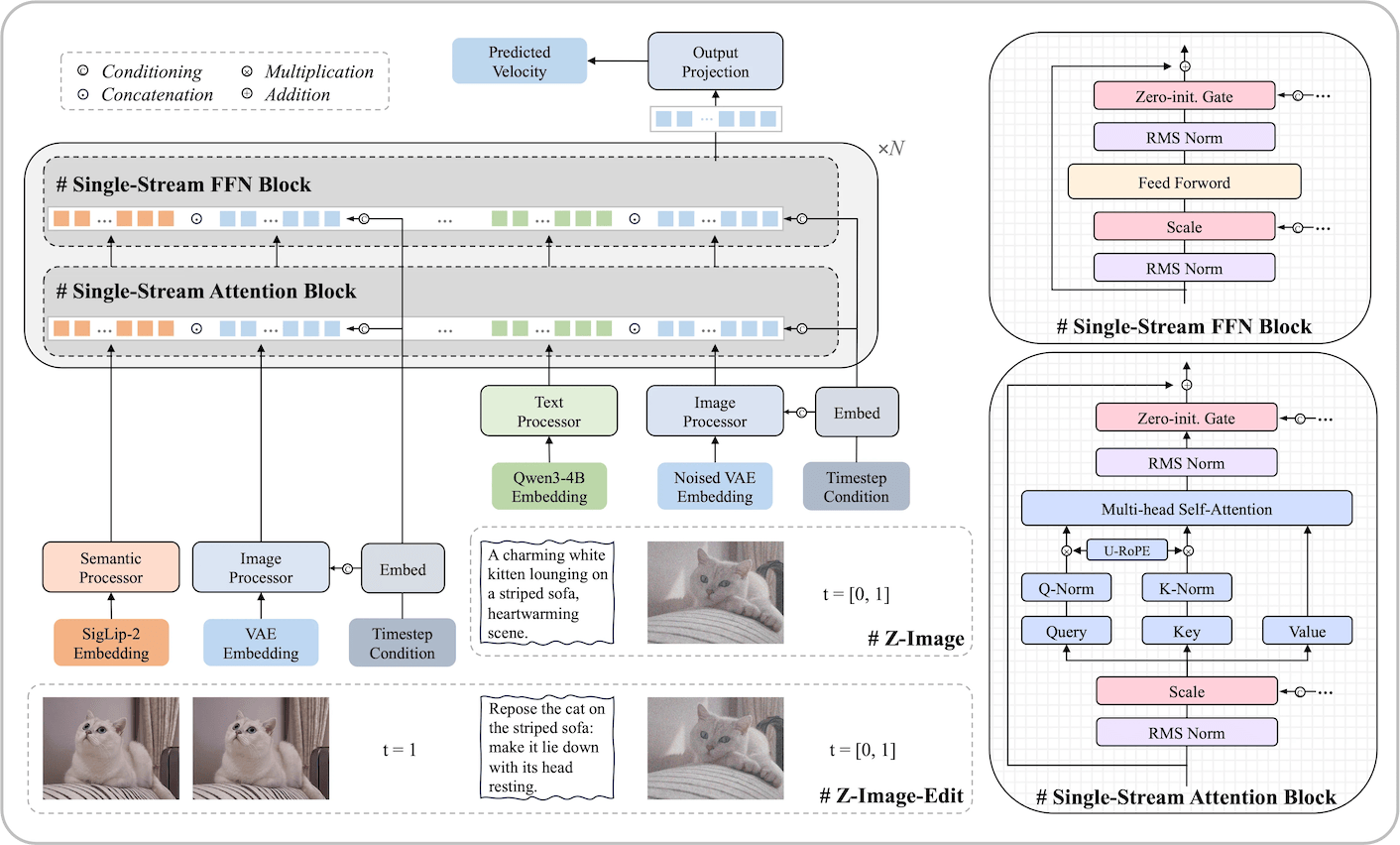
🏗️ 模型架构
我们采用了一种可扩展的单流数字图像处理(S3-DiT)架构。在该架构中,文本、视觉语义标记和图像VAE标记在序列级别上连接起来,作为统一的输入流,与双流方法相比,最大限度地提高了参数效率。
项目链接
模型下载
⏬ 下载
pip install -U huggingface_hub
HF_XET_HIGH_PERFORMANCE=1 hf download Tongyi-MAI/Z-Image-Turbo开源地址
https://github.com/Tongyi-MAI/Z-Image
demo
Hugging Face昨天还可以,今天就删了,大家用来生成色图,导致最开始没限制的模型demo,开始限制,到现在直接删了