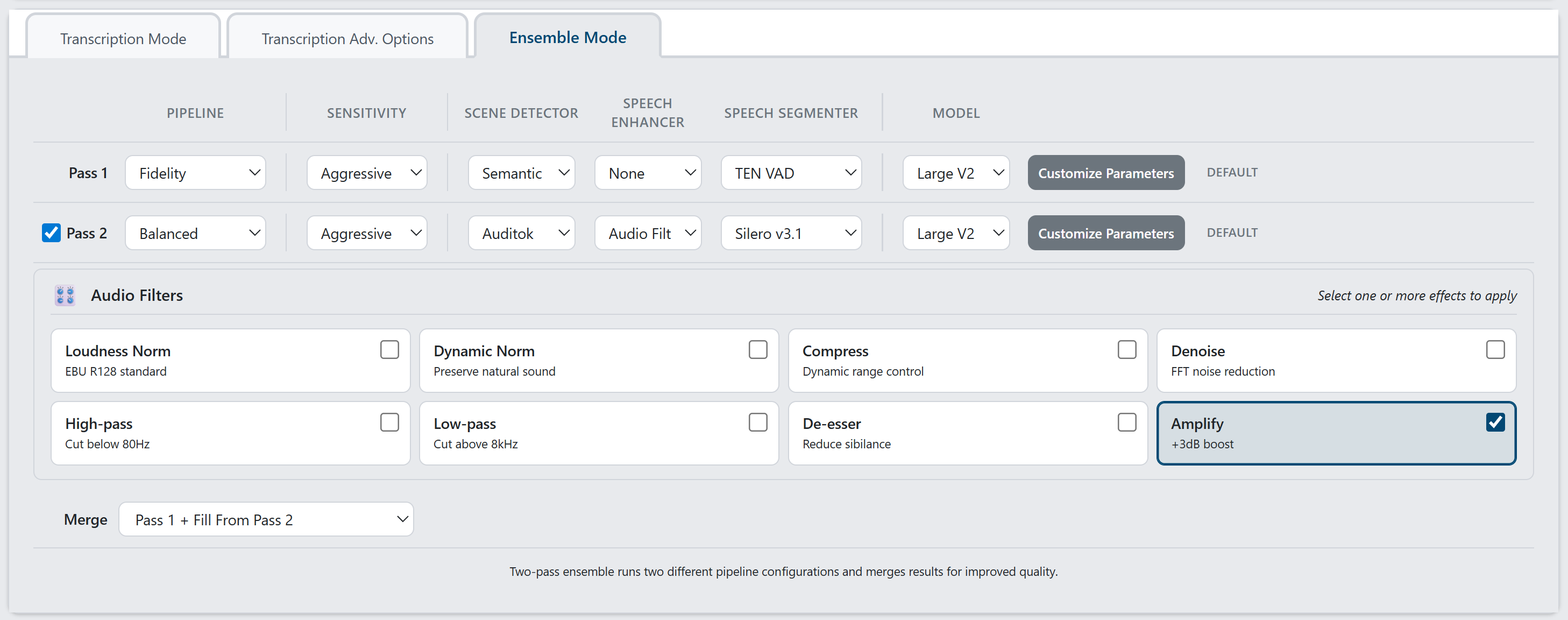
这样就可以在不重新下载 PyTorch(约 2.5GB)或 AI 模型(约 3GB)的情况下更新 WhisperJAV。
从源代码安装
需要 Python 3.9-3.12、FFmpeg 和 Git。
推荐:使用安装脚本(自动处理依赖冲突,自动检测 GPU):视窗
git clone https://github.com/meizhong986/whisperjav.git
cd whisperjav
installer\install_windows.bat # Auto-detects GPU and CUDA version
installer\install_windows.bat --cpu-only # Force CPU only
installer\install_windows.bat --cuda118 # Force CUDA 11.8
installer\install_windows.bat --cuda124 # Force CUDA 12.4
installer\install_windows.bat --minimal # Minimal install (no speech enhancement)
installer\install_windows.bat --dev # Development/editable install
脚本会自动执行以下操作:
检测您的 NVIDIA GPU 并选择最佳 CUDA 版本
如果未找到 GPU,则回退到仅使用 CPU。
检查 WebView2 运行时(GUI 需要)
安装日志install_log_windows.txt
下载失败后最多重试 3 次
Linux / macOS
# Install system dependencies first (Linux only)
# Debian/Ubuntu:
sudo apt-get install -y python3-dev build-essential ffmpeg libsndfile1
# Fedora/RHEL:
sudo dnf install python3-devel gcc ffmpeg libsndfile
git clone https://github.com/meizhong986/whisperjav.git
cd whisperjav
chmod +x installer/install_linux.sh
./installer/install_linux.sh # Auto-detects GPU
./installer/install_linux.sh --cpu-only # Force CPU only
./installer/install_linux.sh --minimal # Minimal install
跨平台 Python 脚本
git clone https://github.com/meizhong986/whisperjav.git
cd whisperjav
python install.py # Auto-detects GPU, defaults to CUDA 12.1
python install.py --cpu-only # CPU only
python install.py --cuda118 # CUDA 11.8
python install.py --cuda121 # CUDA 12.1
python install.py --cuda124 # CUDA 12.4
python install.py --minimal # Minimal install (no speech enhancement)
python install.py --dev # Development/editable install
另一种方法:手动使用 pip 安装(可能会遇到依赖冲突):
# Install PyTorch with GPU support first (NVIDIA example)
pip install torch torchaudio --index-url https://download.pytorch.org/whl/cu124
# Then install WhisperJAV
pip install git+https://github.com/meizhong986/whisperjav.git@main
平台说明:
Apple Silicon(M1/M2/M3/M4):仅pip install torch torchaudio支持 MPS 加速,自动运行。